← return to practice.dsc10.com
These problems are taken from past quizzes and exams. Work on them
on paper, since the quizzes and exams you take in this
course will also be on paper.
We encourage you to complete these
problems during discussion section. Solutions will be made available
after all discussion sections have concluded. You don’t need to submit
your answers anywhere.
Note: We do not plan to cover all of
these problems during the discussion section; the problems we don’t
cover can be used for extra practice.
prices is an array of prices, in dollars, of different
products at the grocery store. Similarly, calories is an
array of the calories in these same products, in the same order.
What does type(prices[0]) evaluate to?
int
float
str
The price of the first product.
Answer: float
prices[0] represents the price in dollars of some
product at the grocery store. The data type should be a
float because prices are numbers but not necessarily
integers.
What does type(calories[0]) evaluate to?
int
float
str
The calories in the first product.
Answer: int
Similarly, calories[0] represents the calories in some
product at the grocery store. The data type should be int
because calories in foods are always reported as integers.
When we divide two arrays of the same length, their corresponding
elements get divided, and the result is a new array of the same length
as the two originals. In one sentence, interpret the meaning of
min(prices / calories).
Answer: This is the cost per calorie of the product which has the lowest cost per calorie, which you might say is the cheapest food to fuel up on (like instant ramen or pasta).
True or False: min(prices / calories) is the same as
max(calories / prices).
Answer: False
The former is measured in dollars per calorie (a very small number), whereas the latter is measured in calories per dollar (a very big number).
However, there is a connection between these two values. The product
that has the lowest price per calorie is the same product with the most
calories per dollar. So these numbers refer to the same grocery store
product, and we can convert one value into the other by taking the
reciprocal, which swaps the numerator and denominator of a fraction.
Therefore, it’s true that min(prices / calories) is the
same as 1 / max(calories / prices).
Consider the following four assignment statements.
bass = "5"
tuna = 2
sword = ["4.0", 5, 12.5, -10, "2023"]
gold = [4, "6", "CSE", "doc"]What is the value of the expression bass * tuna?
Answer: "55"
The average score on this problem was 48%.
Which of the following expressions results in an error?
int(sword[0])
float(sword[1])
int(sword[2])
int(sword[3])
float(sword[4])
Answer: int(sword[0])
The average score on this problem was 51%.
Which of the following expressions evaluates to
"DSC10"?
gold[3].replace("o", "s").title() + str(gold[0] + gold[1])
gold[3].replace("o", "s").upper() + str(gold[0] + int(gold[1]))
gold[3].replace("o", "s").upper() + str(gold[1] + int(gold[0]))
gold[3].replace("o", "s").title() + str(gold[0] + int(gold[1]))
Answer:
gold[3].replace("o", "s").upper() + str(gold[0] + int(gold[1]))
The average score on this problem was 92%.
Evaluate the expression
(np.arange(1, 7, 2.5) * np.arange(8, 2, -2))[2] .
Answer: 24.0
This question although is daunting at first, is best solved by
breaking up the question into parts. First, let us think about the first
part, np.arange(1, 7, 2.5). In order to answer this, we
must figure out what np.arange() does. What
np.arange() does is it creates a numpy array
that contains regularly spaced values between a start value and an end
value (start is inclusive, end is exclusive). So in this first case, our
starting value is 1, our end value is 7, and the regular interval or
step size is 2.5. So this call, np.arange(1, 7, 2.5), will
output the numpy array
np.array([1.0, 3.5, 6.0]) because we start at 1, and
continue adding 2.5 stopping at the last value that’s less than 7. The
reason the resulting np.array([1.0, 3.5, 6.0]) contains all
float values is because one of the numbers is not an
int, and all elements in the array have to have the same
data type. Now that we have evaluated the first half, let us now solve
for np.arange(8, 2, -2). Now this part may seem a little
tricky because of the negative regular interval (step size), but it is
the same logic as before. The output will simply be
np.array([8, 6, 4]). In order to get that, we start at 8,
and continue to decrease our start value by 2 stopping before we reach
2. Now that we have evaluated both np.arange(1, 7, 2.5) and
np.arange(8, 2, -2), it is now time to multiply.
Multiplication of two numpy arrays is simply pairwise
multiplication. So in our case, we will be multiplying
np.array([1.0, 3.5, 6.0]) * np.array([8, 6, 4]), which
results to np.array([8.0, 21.0, 24.0]). Again, paying
attention to the datatypes, the reason that
np.array([8.0, 21.0, 24.0]) contains float
values rather than int values is because when you multiply
an int by a float, your answer will be a
float. Now that we have evaluated
(np.arange(1, 7, 2.5) * np.arange(8, 2, -2)) to be
np.array([8.0, 21.0, 24.0]), we now just need to access the
element in position 2, which is 24.0.
Suppose x and y are both ints
that have been previously defined, with x < y. Now,
define:
peach = np.arange(x, y, 2)Say that the spread of peach is the difference
between the largest and smallest values in peach. The
spread should be a non-negative integer.
Using array methods, write an expression that
evaluates to the spread of peach.
Answer: peach.max() - peach.min()
The average score on this problem was 62%.
Without using any methods or functions, write an
expression that evaluates to the spread of peach.
Hint: Use [ ].
Answer:
peach[len(peach) - 1] - peach[0] or
peach[-1] - peach[0]
The average score on this problem was 36%.
Choose the correct way to fill in the blank in this sentence:
The spread of peach is ______ the
value of y - x.
always less than
sometimes less than and sometimes equal to
always greater than
sometimes greater than and sometimes equal to
always equal to
Answer: always less than
The average score on this problem was 48%.
Consider the following assignment statement.
puffin = np.array([5, 9, 13, 17, 21])Provide arguments to call np.arange with so that the
array penguin is identical to the array
puffin.
penguin = np.arange(____)Answer: We need to provide np.arange
with three arguments: 5, anything in (21,
25], 4. For instance, something like
penguin = np.arange(5, 25, 4) would work.
The average score on this problem was 90%.
Fill in the blanks so that the array parrot is also
identical to the array puffin.
Hint: Start by choosing y so that
parrot has length 5.
parrot = __(x)__ * np.arange(0, __(y)__, 2) + __(z)__Answer:
x: 2y: anything in (8,
10]z: 5
The average score on this problem was 74%.
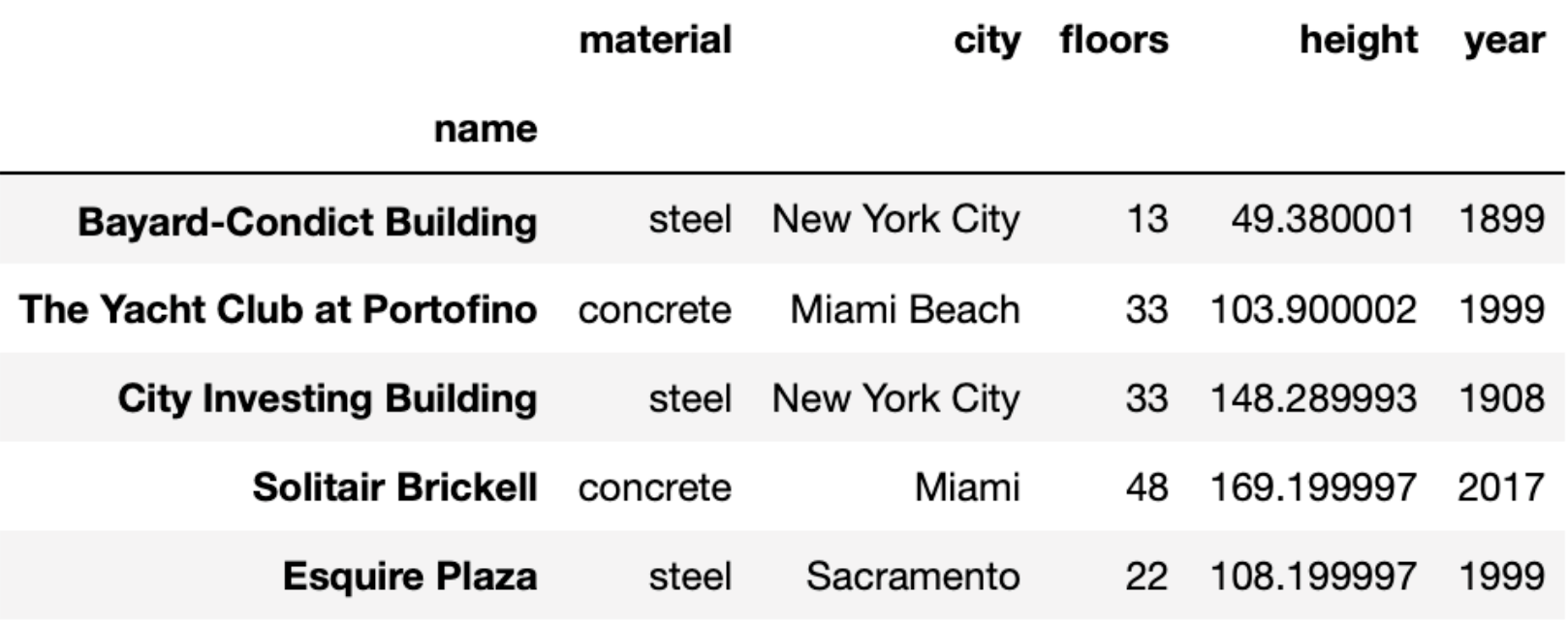
sky. The first few rows of
sky are shown below (though the full DataFrame has more
rows):
Each row of sky corresponds to a single skyscraper. For
each skyscraper, we have:
its name, which is stored in the index of sky
(string)
the 'material' it is made up of (string)
the 'city' in the US where it is located
(string)
the number of 'floors' (levels) it contains
(int)
its 'height' in meters (float), and
the 'year' in which it was opened (int)
Below, identify the data type of the result of each of the following expressions, or select “error” if you believe the expression results in an error.
sky.sort_values('height')int or float
Boolean
string
array
Series
DataFrame
error
Answer: DataFrame
sky is a DataFrame. All the sort_values
method does is change the order of the rows in the Series/DataFrame it
is called on, it does not change the data structure. As such,
sky.sort_values('height') is also a DataFrame.
The average score on this problem was 87%.
sky.sort_values('height').get('material').loc[0]int or float
Boolean
string
array
Series
DataFrame
error
Answer: error
sky.sort_values('height') is a DataFrame, and
sky.sort_values('height').get('material') is a Series
corresponding to the 'material' column, sorted by
'height' in increasing order. So far, there are no
errors.
Remember, the .loc accessor is used to access
elements in a Series based on their index.
sky.sort_values('height').get('material').loc[0] is asking
for the element in the
sky.sort_values('height').get('material') Series with index
0. However, the index of sky is made up of building names.
Since there is no building named 0, .loc[0]
causes an error.
The average score on this problem was 79%.
sky.sort_values('height').get('material').iloc[0]int or float
Boolean
string
array
Series
DataFrame
error
Answer: string
As we mentioned above,
sky.sort_values('height').get('material') is a Series
containing values from the 'material' column (but sorted).
Remember, there is no element in this Series with an index of 0, so
sky.sort_values('height').get('material').loc[0] errors.
However, .iloc[0] works differently than
.loc[0]; .iloc[0] will give us the first
element in a Series (independent of what’s in the index). So,
sky.sort_values('height').get('material').iloc[0] gives us
back a value from the 'material' column, which is made up
of strings, so it gives us a string. (Specifically, it gives us the
'material' type of the skyscraper with the smallest
'height'.)
The average score on this problem was 89%.
sky.get('floors').max()int or float
Boolean
string
array
Series
DataFrame
error
Answer: int or float
The Series sky.get('floors') is made up of integers, and
sky.get('floors').max() evaluates to the largest number in
the Series, which is also an integer.
The average score on this problem was 91%.
sky.index[0]int or float
Boolean
string
array
Series
DataFrame
error
Answer: string
sky.index contains the values
'Bayard-Condict Building',
'The Yacht Club at Portofino',
'City Investing Building', etc. sky.index[0]
is then 'Bayard-Condict Building', which is a string.
The average score on this problem was 91%.
Write a single line of code that evaluates to the name of the tallest
skyscraper in the sky DataFrame.
Answer:
sky.sort_values(by='height', ascending=False).index[0]
In order to answer this question, we must first sort the values of
the column we are interested in. As such, we sort the entire DataFrame
by the height column, and because we are interested in the
name of the tallest building, we should set the ascending
parameter to False because we would like the heights to be
ordered in descending order, thus leading to the line
sky.sort_values(by='height', ascending=False). After
sorting in descending order, we know that the tallest building is going
to be the first row of the new sky DataFrame, and thus we
now only need to get the name of the skyscraper, which happens to be in
the index. In order to access the index of the DataFrame we can use
sky.index, and in our case because we know that we want the
first index, we would need to write sky.index[0]. Finally,
putting it all together, in order to get the name of the tallest
skyscraper in the sky DataFrame, we would need to write
sky.sort_values(by='height', ascending=False).index[0].
Write a single line of code that evaluates to the average number of floors across all skyscrapers in the DataFrame.
Answer: sky.get('floors').mean()
In order to answer the question, we must first figure out how to get
the number of floors each skyscraper has. We can do this with a line of
code like sky.get('floors') which will get the number of
floors each skyscraper has. After doing this, we now need to find out
the average number of floors each skyscraper has. We can do this by
using the .mean() method, which in our case will get the
average number of floors each skyscraper has. Putting this all together,
we get a line of code that looks like
sky.get('floors').mean().
Suppose students is a DataFrame of all students who took
DSC 10 last quarter. students has one row per student,
where:
The index contains students’ PIDs as strings starting with
"A".
The "Overall" column contains students’ overall
percentage grades as floats.
The "Animal" column contains students’ favorite
animals as strings.
What type is students.get("Overall")? If this expression
errors, select “this errors."
float
string
array
Series
this errors
Answer: Series
The average score on this problem was 73%.
What type is students.get("PID")? If this expression
errors, select “this errors."
float
string
array
Series
this errors
Answer: this errors
The average score on this problem was 67%.
Vanessa is one student who took DSC 10 last quarter. Her PID is A12345678, she earned the sixth-highest overall percentage grade in the class, and her favorite animal is the giraffe.
Supposing that students is already sorted by
"Overall" in descending order, fill in the
blanks so that animal_one and animal_two
both evaluate to "giraffe".
animal_one = students.get(__(x)__).loc[__(y)__]
animal_two = students.get(__(x)__).iloc[__(z)__]Answer:
x: "Animal"y: "A12345678"z: 5
The average score on this problem was 69%.
If students wasn’t already sorted by
"Overall" in descending order, which of your answers would
need to change?
Neither y nor z would need to change
Both y and z would need to change
y only
z only
Answer: z only
The average score on this problem was 82%.
You are given a DataFrame called sports, indexed by
'Sport' containing one column,
'PlayersPerTeam'. The first few rows of the DataFrame are
shown below:
| Sport | PlayersPerTeam |
|---|---|
| baseball | 9 |
| basketball | 5 |
| field hockey | 11 |
Which of the following evaluates to
'basketball'?
sports.loc[1]
sports.iloc[1]
sports.index[1]
sports.get('Sport').iloc[1]
Answer: sports.index[1]
We are told that the DataFrame is indexed by 'Sport' and
'basketball' is one of the elements of the index. To access
an element of the index, we use .index to extract the index
and square brackets to extract an element at a certain position.
Therefore, sports.index[1] will evaluate to
'basketball'.
The first two answer choices attempt to use .loc or
.iloc directly on a DataFrame. We typically use
.loc or .iloc on a Series that results from
using .get on some column. Although we don’t typically do
it this way, it is possible to use .loc or
.iloc directly on a DataFrame, but doing so would produce
an entire row of the DataFrame. Since we want just one word,
'basketball', the first two answer choices must be
incorrect.
The last answer choice is incorrect because we can’t use
.get with the index, only with a column. The index is never
considered a column.
The average score on this problem was 88%.
Suppose you are given a DataFrame of employees for a given company.
The DataFrame, called employees, is indexed by
'employee_id' (string) with a column called
'years' (int) that contains the number of years each
employee has worked for the company.
Suppose that the code
employees.sort_values(by='years', ascending=False).index[0]outputs '2476'.
True or False: The number of years that employee 2476 has worked for the company is greater than the number of years that any other employee has worked for the company.
True
False
Answer: False
This is false because there could be other employees who worked at the company equally long as employee 2476.
The code says that when the employees DataFrame is
sorted in descending order of 'years', employee 2476 is in
the first row. There might, however, be a tie among several employees
for their value of 'years'. In that case, employee 2476 may
wind up in the first row of the sorted DataFrame, but we cannot say that
the number of years employee 2476 has worked for the company is greater
than the number of years that any other employee has worked for the
company.
If the statement had said greater than or equal to instead of greater than, the statement would have been true.
The average score on this problem was 29%.
What will be the output of the following code?
employees.assign(start=2021-employees.get('years'))
employees.sort_values(by='start').index.iloc[-1]the employee id of an employee who has worked there for the most years
the employee id of an employee who has worked there for the fewest years
an error message complaining about iloc[-1]
an error message complaining about something else
Answer: an error message complaining about something else
The problem is that the first line of code does not actually add a
new column to the employees DataFrame because the
expression is not saved. So the second line tries to sort by a column,
'start', that doesn’t exist in the employees
DataFrame and runs into an error when it can’t find a column by that
name.
This code also has a problem with iloc[-1], since
iloc cannot be used on the index, but since the problem
with the missing 'start' column is encountered first, that
will be the error message displayed.
The average score on this problem was 27%.