
← return to practice.dsc10.com
Below are practice problems tagged for Lecture 10 (rendered directly from the original exam/quiz sources).
We define the seasons as follows:
| Season | Month |
|---|---|
| Spring | March, April, May |
| Summer | June, July, August |
| Fall | September, October, November |
| Winter | December, January, February |
We want to create a function date_to_season that takes
in a date as formatted in the 'DATE' column of
flights and returns the season corresponding to that date.
Which of the following implementations of date_to_season
works correctly? Select all that apply.
Option 1:
def date_to_season(date):
month_as_num = int(date.split('-')[1])
if month_as_num >= 3 and month_as_num < 6:
return 'Spring'
elif month_as_num >= 6 and month_as_num < 9:
return 'Summer'
elif month_as_num >= 9 and month_as_num < 12:
return 'Fall'
else:
return 'Winter'Option 2:
def date_to_season(date):
month_as_num = int(date.split('-')[1])
if month_as_num >= 3 and month_as_num < 6:
return 'Spring'
if month_as_num >= 6 and month_as_num < 9:
return 'Summer'
if month_as_num >= 9 and month_as_num < 12:
return 'Fall'
else:
return 'Winter'Option 3:
def date_to_season(date):
month_as_num = int(date.split('-')[1])
if month_as_num < 3:
return 'Winter'
elif month_as_num < 6:
return 'Spring'
elif month_as_num < 9:
return 'Summer'
elif month_as_num < 12:
return 'Fall'
else:
return 'Winter' Option 1
Option 2
Option 3
None of these implementations of date_to_season work
correctly
Answer: Option 1, Option 2, Option 3
All three options start with the same first line of code:
month_as_num = int(date.split('-')[1]). This takes the
date, originally a string formatted such as '2021-09-07',
separates it into a list of three strings such as
['2021', '09', '07'], extracts the element in position 1
(the middle position), and converts it to an int such as 9.
Now we have the month as a number we can work with more easily.
According to the definition of seasons, the months in each season are as follows:
| Season | Month | month_as_num |
|---|---|---|
| Spring | March, April, May | 3, 4, 5 |
| Summer | June, July, August | 6, 7, 8 |
| Fall | September, October, November | 9, 10, 11 |
| Winter | December, January, February | 12, 1, 2 |
Option 1 correctly assigns months to seasons by checking if the month
falls in the appropriate range for 'Spring', then
'Summer', then 'Fall'. Finally, if all of
these conditions are false, the else branch will return the
correct answer of 'Winter' when month_as_num
is 12, 1, or 2.
Option 2 is also correct, and in fact, it does the same exact thing
as Option 1 even though it uses if where Option 1 used
elif. The purpose of elif is to check a
condition only when all previous conditions are false. So if we have an
if followed by an elif, the elif
condition will only be checked when the if condition is
false. If we have two sequential if conditions, typically
the second condition will be checked regardless of the outcome of the
first condition, which means two if statements can behave
differently than an if followed by an elif. In
this case, however, since the if statements cause the
function to return and therefore stop executing, the only
way to get to a certain if condition is when all previous
if conditions are false. If any prior if
condition was true, the function would have returned already! So this
means the three if conditions in Option 2 are equivalent to
the if, elif, elif structure of
Option 1. Note that the else case in Option 1 is reached
when all prior conditions are false, whereas the else in
Option 2 is paired only with the if statement immediately
preceding it. But since we only ever get to that third if
statement when the first two if conditions are false, we
still only reach the else branch when all three
if conditions are false.
Option 3 works similarly to Option 1, except it separates the months
into more categories, first categorizing January and February as
'Winter', then checking for 'Spring',
'Summer', and 'Fall'. The only month that
winds up in the else branch is December. We can think of
Option 3 as the same as Option 1, except the Winter months have been
separated into two groups, and the group containing January and February
is extracted and checked first.
The average score on this problem was 76%.
Assuming we’ve defined date_to_season correctly in the
previous part, which of the following lines of code correctly computes
the season for each flight in flights?
date_to_season(flights.get('DATE'))
date_to_season.apply(flights).get('DATE')
flights.apply(date_to_season).get('DATE')
flights.get('DATE').apply(date_to_season)
Answer:
flights.get('DATE').apply(date_to_season)
Our function date_to_season takes as input a single date
and converts it to a season. We cannot input a whole Series of dates, as
in the first answer choice. We instead need to apply the
function to the whole Series of dates. The correct syntax to do that is
to first extract the Series of dates from the DataFrame and then use
.apply, passing in the name of the function we wish to
apply to each element of the Series. Therefore, the correct answer is
flights.get('DATE').apply(date_to_season).
The average score on this problem was 97%.
Consider the function tom_nook, defined below. Recall
that if x is an integer, x % 2 is
0 if x is even and 1 if
x is odd.
def tom_nook(crossing):
bells = 0
for nook in np.arange(crossing):
if nook % 2 == 0:
bells = bells + 1
else:
bells = bells - 2
return bellsWhat value does tom_nook(8) evaluate to?
-6
-4
-2
0
2
4
6
Answer: -4
The average score on this problem was 79%.
ISBN numbers for books must follow a very particular format. The first 12 digits encode a lot of information about a book, including the publisher, edition, and physical properties like page count. The 13th and final digit, however, is computed directly from the first 12 digits and is used to verify that a given ISBN number is valid.
In this question, we will define a function to compute the final digit of an ISBN number, given the first 12. First, we need to understand how the last digit is determined. To find the last digit of an ISBN number:
Multiply the first digit by 1, the second digit by 3, the third digit by 1, the fourth digit by 3, and so on, alternating 1s and 3s.
Add up these products.
Find the ones digit of this sum.
If the ones digit of the sum is zero, the final digit of the ISBN is zero. Otherwise, the final digit of the ISBN is ten minus the ones digit of the sum.
For example, suppose we have an ISBN number whose first 12 digits are 978186197271. Then the last digit would be calculated as follows: 9\cdot 1 + 7\cdot 3 + 8\cdot 1 + 1\cdot 3 + 8\cdot 1 + 6\cdot 3 + 1\cdot 1 + 9\cdot 3 + 7\cdot 1 + 2\cdot 3 + 7\cdot 1 + 1\cdot 3 = 118 The ones digit is 8 so the final digit is 2.
Fill in the blanks in the function calculate_last_digit
below. This function takes as input a string
representing the first 12 digits of the ISBN number, and should return
the final digit of the ISBN number, as an int. For example,
calculate_last_digit("978186197271") should evaluate to
2.
def calculate_last_digit(partial_isbn_string):
total = 0
for i in __(a)__:
digit = int(partial_isbn_string[i])
if __(b)__:
total = total + digit
else:
total = total + 3 * digit
ones_digit = __(c)__
if __(d)__:
return 10 - ones_digit
return 0Note: this procedure may seem complicated, but it is actually how the last digit of an ISBN number is generated in real life!
np.arange(12) or np.arange(len(partial_isbn_string))We need to loop through all of the digits in the partial string we are given.
The average score on this problem was 62%.
i % 2 == 0 or i in [0, 2, 4, 6, 8, 10]If we are at an even position, we want to add the digit itself (or the digit times 1). We can check if we are at an even positon by checking the remainder upon division by 2, which is 0 for all even numbers and 1 for all odd numbers.
The average score on this problem was 41%.
total % 10 or int(str(total)[-1])We need the ones digit of the total to determine what to return. We
can treat total as an integer and get the ones digit by
finding the remainder upon division by 10, or we can convert
total to a string, extract the last character with
[-1], and then convert back to an int.
The average score on this problem was 44%.
ones_digit != 0In most cases, we subtract the ones digit from 10 and return that. If the ones digit is 0, we just return 0.
The average score on this problem was 87%.
Define the function puzzle as below.
def puzzle(word):
if not(len(word) > 2):
return False
elif word in "UC San Diego":
return True
else:
return not("UC" in word) Select all the function calls that evaluate to True.
puzzle("UC San")
puzzle("UC")
puzzle("UCB")
puzzle("HDSI")
Answer:
puzzle("UC San")puzzle("HDSI")
The average score on this problem was 74%.
The function below classifies the length of a word as
"short", "medium", or "long". Its
input, x, represents the length of a word and will always
be a positive integer.
def classify_length(x):
if x <= 6:
return "short"
elif x <= 10:
return "medium"
else:
return "long"Fill in the blanks of the function below so that
classify_length_2 gives the same output as
classify_length on all positive integer inputs. Each blank
must be filled in with a single line of code.
def classify_length_2(x):
if __(a)__:
return "medium"
if x >= 7:
__(b)__
__(c)__(a): x > 6 and x <= 10
We know that we need to return medium given this condition, so the
answer is x > 6 and x <= 10. x > 6 comes from the
short condition, x = 10 is in the original classify length.
(b): return "long"
Since the condition has x be larger, we know that we should
return "long".
(c): return "short".
This will be the last, non-covered classification, so it should be
return "short".
The average score on this problem was 79%.
IKEA is piloting a new rewards program where customers can earn free Swedish meatball plates from the in-store cafe when they purchase expensive items. Meatball plates are awarded as follows. Assume the item price is always an integer.
| Item price | Number of meatball plates |
|---|---|
| less than 99 dollars | 0 |
| 100 to 199 dollars | 1 |
| 200 dollars or more | 2 |
We want to implement a function called
calculate_meatball_plates that takes as input an array of
several item prices, corresponding to the individual items purchased in
one transaction, and returns the total number of meatball plates earned
in that transaction.
Select all correct ways of implementing this function from the options below.
Way 1:
def calculate_meatball_plates(prices):
meatball_plates = 0
for price in prices:
if price >= 100 and price <= 199:
meatball_plates = 1
elif price >= 200:
meatball_plates = 2
return meatball_platesWay 2:
def calculate_meatball_plates(prices):
meatball_plates = 0
for price in prices:
if price >= 200:
meatball_plates = meatball_plates + 1
if price >= 100:
meatball_plates = meatball_plates + 1
return meatball_platesWay 3:
def calculate_meatball_plates(prices):
return np.count_nonzero(prices >= 100) + np.count_nonzero(prices >= 200)Way 4:
def calculate_meatball_plates(prices):
return (prices >= 200).sum()*2 + ((100 <= prices) & (prices <= 199)).sum()*1Way 1
Way 2
Way 3
Way 4
Answer: Way 2, Way 3, Way 4
Way 1 does not work because it resets the variable
meatball_plates with each iteration instead of adding to a
running total. At the end of the loop, meatball_plates
evaluates to the number of meatball plates earned by the last price in
prices instead of the total number of meatball plates
earned by all purchases. A quick way to see this is incorrect is to
notice that the only possible return values are 0, 1, and 2, but it’s
possible to earn more than 2 meatball plates with enough purchases.
Way 2 works. As in Way 1, it loops through each price in
prices. When evaluating each price, it checks if the price
is at least 200 dollars, and if so, increments the total number of
meatball plates by 1. Then it checks if the price is at least 100
dollars, and if so, increments the count of meatball plates again. This
works because for prices that are at least 200 dollars, both
if conditions are satisfied, so the meatball plate count
goes up by 2, and for prices that are between 100 and 199 dollars, only
one of the if conditions is satisfied, so the count
increases by 1. For prices less than 100 dollars, the count doesn’t
change.
Way 3 works without using any iteration at all. It uses
np.count_nonzero to count the number of prices that are at
least 100 dollars, then it similarly counts the number of prices that
are at least 200 dollars and adds these together. This works because
prices that are at least 200 dollars are also at least 100 dollars, so
they contribute 2 to the total. Prices that are between 100 and 199
contribute 1, and prices below 100 dollars don’t contribute at all.
Way 4 also works and calculates the number of meatball plates without
iteration. The expression prices >= 200 evaluates to a
boolean Series with True for each price that is at least 200 dollars.
Summing this Series gives a count of the number of prices that are at
least 200 dollars, since True counts as 1 and False counts as 0 in
Python. Each such purchase earns 2 meatball plates, so this count of
purchases 200 dollars and up gets multiplied by 2. Similarly,
(100 <= prices) & (prices <= 199) is a Series
containing True for each price that is at least 100 dollars and at most
199 dollars, and the sum of that Series is the number of prices between
100 and 199 dollars. Each such purchase contributes one additional
meatball plate, so the number of such purchases gets multiplied by 1 and
added to the total.
The average score on this problem was 64%.
Consider an artist that has only appeared once at Sun God. At the time of their Sun God performance, we’ll call the artist
Complete the function below so it outputs the appropriate description for any input artist who has appeared exactly once at Sun God.
def classify_artist(artist):
filtered = merged[merged.get('Artist') == artist]
year = filtered.get('Year').iloc[0]
top_hit_year = filtered.get('Top_Hit_Year').iloc[0]
if ___(a)___ > 0:
return 'up-and-coming'
elif ___(b)___:
return 'outdated'
else:
return 'trending'What goes in blank (a)?
Answer: top_hit_year - year
Before we can answer this question, we need to understand what the
first three lines of the classify_artist function are
doing. The first line creates a DataFrame with only one row,
corresponding to the particular artist that’s passed in as input to the
function. We know there is just one row because we are told that the
artist being passed in as input has appeared exactly once at Sun God.
The next two lines create two variables:
year contains the year in which the artist performed at
Sun God, andtop_hit_year contains the year in which their top hit
song was released.Now, we can fill in blank (a). Notice that the body of the
if clause is return 'up-and-coming'. Therefore
we need a condition that corresponds to up-and-coming, which we are told
means the top hit came out after the artist appeared at Sun God. Using
the variables that have been defined for us, this condition is
top_hit_year > year. However, the if
statement condition is already partially set up with > 0
included. We can simply rearrange our condition
top_hit_year > year by subtracting year
from both sides to obtain top_hit_year - year > 0, which
fits the desired format.
The average score on this problem was 89%.
What goes in blank (b)?
Answer: year-top_hit_year > 5
For this part, we need a condition that corresponds to an artist
being outdated which happens when their top hit came out more than five
years prior to their appearance at Sun God. There are several ways to
state this condition: year-top_hit_year > 5,
year > top_hit_year + 5, or any equivalent condition
would be considered correct.
The average score on this problem was 89%.
For each city in sun, we have 12 numbers, corresponding
to the number of sunshine hours it sees in January, February, March, and
so on, through December. (There is also technically a 13th number, the
value in the "Year" column, but we will ignore it for the
purposes of this question.)
We say that a city’s number of sunshine hours peaks gradually if both of the following conditions are true:
Each month from February to June has a number of sunshine hours greater than or equal to the month before it.
Each month from August to December has a number of sunshine hours less than or equal to the month before it.
For example, the number of sunshine hours per month in Doris’ hometown of Guangzhou, China peaks gradually:
62, 65, 71, 104, 118, 202, 181, 173, 172, 170, 166, 140
However, the number of sunshine hours per month in Charlie’s hometown of Redwood City, California does not peak gradually, since 325 > 311 and 247 < 271:
185, 207, 269, 309, 325, 311, 313, 287, 247, 271, 173, 160
Complete the implementation of the function
peaks_gradually, which takes in an array hours
of length 12 corresponding to the number of sunshine hours per month in
a city, and returns True if the city’s number of sunshine
hours peaks gradually and False otherwise.
def peaks_gradually(hours):
for i in np.arange(5):
cur_left = hours[5 - i]
next_left = hours[__(a)__]
cur_right = hours[__(b)__]
next_right = hours[6 + i + 1]
if __(c)__:
__(d)__
__(e)__What goes in blank (a)?
Answer: 5 - i - 1 or
4 - i
Before filling in the blanks, let’s discuss the overall strategy of the problem. The idea is as follows
cur_left, which is the sunshine hours for June
(month 5, since 5 - i = 5 - 0 = 5), to
next_left, which is the sunshine hours for May (month 5 - i - 1 = 4). If
next_left > cur_left, it means that May has more
sunshine hours than June, which means the sunshine hours for this city
don’t peak gradually. (Remember, for the number of sunshine hours to
peak gradually, we need it to be the case that each month from February
to June has a number of sunshine hours greater than or equal to the
month before it.)cur_right, which is the sunshine hours
for July (month 6, since 6 + i = 6 + 0 =
6), to next_right, which is the sunshine hours for
August (month 6 + i + 1 = 7). If
next_right > cur_right, it means that August has more
sunshine hours than July, which means the sunshine hours for this city
don’t peak gradually. (Remember, for the number of sunshine hours to
peak gradually, we need it to be the case that each month from August to
December has a number of sunshine hours less than or equal to the month
before it.)next_left > cur_left or next_right > cur_right, then
we don’t need to look at any other pairs of months, and can just
return False. Otherwise, we keep looking.cur_left
and next_left will “step backwards” and refer to May (month
4, since 5 - i = 5 - 1 = 4) and April
(month 3, since 5 - i - 1 = 3),
respectively. Simililarly, cur_right and
next_right will “step forwards” and refer to August and
September, respectively. The above process is repeated.next_left > cur_left or next_right > cur_right was
never True, then it must be the case that the sunshine
hours for this city peak gradually, and we can return True
outside of the for-loop!Focusing on blank (a) specifically, it needs to contain the position
of next_left, which is the index of the month before the
current left month. Since the current month is at 5 - i,
the next month needs to be at 5 - i - 1.
The average score on this problem was 62%.
What goes in blank (b)?
Answer: 6 + i
Using the same logic as for blank (a), blank (b) needs to contain the
position of cur_right, which is the index of the month
before the next right month. Since the next right month is at
6 + i + 1, the current right month is at
6 + i.
The average score on this problem was 67%.
What goes in blank (c)?
next_left < cur_left or next_right < cur_right
next_left < cur_left and next_right < cur_right
next_left > cur_left or next_right > cur_right
next_left > cur_left and next_right > cur_right
Answer:
next_left > cur_left or next_right > cur_right
Explained in the answer to blank (a).
The average score on this problem was 35%.
What goes in blank (d)?
return True
return False
Answer: return False
Explained in the answer to blank (a).
The average score on this problem was 50%.
What goes in blank (e)?
return True
return False
Answer: return True
Explained in the answer to blank (a).
The average score on this problem was 54%.
Currently, the "Section" column of survey
contains the values "A" and "B". However, it’s
more natural to think of the lecture sections in terms of their times,
i.e. "12PM" and "1PM".
Below, we’ve defined four functions, named converter_1,
converter_2, converter_3, and
converter_4. All four functions return "12PM"
when "A" is the argument passed in and return
"1PM" when "B" is the argument passed in.
Where they potentially differ is in how they behave when called on
arguments other than "A" and "B".
Note: In the answer choices below, by None we mean that
the function call doesn’t return anything, but doesn’t error either.
Consider the function converter_1, defined below.
def converter_1(section):
if section == "A":
return "12PM"
else:
return "1PM"When convert_1 is called on an argument other than
"A" or "B", what does it return?
"12PM"
"1PM"
None
It errors
Consider the function converter_2, defined below.
def converter_2(section):
time_dict = {
"A": "12PM",
"B": "1PM"
}
return times_dict[section]When convert_2 is called on an argument other than
"A" or "B", what does it return?
"12PM"
"1PM"
None
It errors
Consider the function converter_3, defined below.
def converter_3(section):
if section == "A":
return "12PM"
elif section == "B":
return "1PM"
else:
return 1 / 0When converter_3 is called on an argument other than "A"
or "B", what does it return?
"12PM"
"1PM"
None
It errors
Consider the function converter_4, defined below.
def converter_4(section):
sections = ["A", "B"]
times = ["12PM", "1PM"]
for i in np.arange(len(sections)):
if section == sections[i]:
return times[i]When converter_4 is called on an argument other than
"A" or "B", what does it return?
"12PM"
"1PM"
None
It errors
Answer: converter_1:
"1PM", converter_2: It errors,
converter_3: It errors, converter_4:
None.
converter_1: "1PM". The function
converter_1 checks if the input section is
equal to "A". If it is, the function returns
"12PM". However, if the input is anything other than
"A" (including values other than "B"), the
function defaults to the else condition and returns
"1PM". So, even for arguments other than "A"
or "B", converter_1 will return
"1PM".
The average score on this problem was 90%.
converter_2: It errors. The function
converter_2 utilizes a dictionary (time_dict)
to map section values to their corresponding times. When a key that
doesn’t exist in the dictionary is accessed (anything other than
"A" or "B"), a KeyError is raised, causing the
function to error.
The average score on this problem was 62%.
converter_3: It errors. The function
converter_3 specifically checks if the input section is
"A" or "B". If the input is neither
"A" nor "B", the function defaults to the else
condition where it tries to divide 1 by 0.
This operation will cause a ZeroDivisionError, leading the function to
error.
The average score on this problem was 90%.
converter_4: None. The function
converter_4 uses two lists, sections and
times, to map the section letters "A" and
"B" to their corresponding times "12PM" and
"1PM". The function then employs a for-loop to
traverse through the sections list. The expression
range(len(sections)) is used to generate a sequence of
indices for this list; since len(sections) is 2,
np.arange(len(sections)) is the array
np.array([0, 1]). Then, - Inside the loop, the condition if
section == sections[i] checks if the input section matches
the section at the current index i of the
sections list. If a match is found, the function returns
the corresponding time from the times list using
return times[i]. - However, if the function traverses the
entire sections list without finding a match (i.e., the
input is neither "A" nor "B"), no
return statement is executed. In Python, if a function
completes its execution without encountering a return
statement, it implicitly returns the value None. Hence, for
inputs other than "A" or "B",
converter_4 will return None.
The average score on this problem was 77%.
Suppose we decide to use converter_4 to convert the
values in the "Section" column of survey to
times. To do so, we first use the .apply method, like
so:
section_times = survey.get("Section").apply(converter_4)What is the type of section_times?
int or float
Boolean
string
list or array
Series
DataFrame
We’d then like to replace the "Section" column in
survey with the results in section_times. To
do so, we run the following line of code, after running the assignment
statement above:
survey.assign(Section="section_times")What is the result of running the above line of code?
The "Section" column in survey now contains
only the values "12PM" and "1PM".
The line evaluates to a new DataFrame whose "Section"
column only contains the values "12PM" and
"1PM", but the "Section" column in
survey still contains the values "A" and
"B".
An error is raised, because we can’t use .assign with a
column name that already exists.
An error is raised, because the value after the = needs
to be a list, array, or Series, not a string.
An error is raised, because the value before the = needs
to be a string, not a variable name.
Answer:
What is the type of section_times?
Series. When the .apply() method is used on a
Series in a DataFrame, it applies the given function to each element in
the Series and returns a new Series with the transformed values. Thus,
the type of section_times is a Series.
The average score on this problem was 76%.
What is the result of running the above line of code? An
error is raised, because the value after the = needs to be
a list, array, or Series, not a string. The
.assign method is used to add new columns or modify
existing columns in a DataFrame. The correct usage would have been to
provide the actual Series section_times without quotes. The
provided line mistakenly provides a string "section_times"
instead of the actual variable, leading to an error.
The average score on this problem was 52%.
After being selected at the reaping, tributes are transported to the Capitol to prepare for the Hunger Games. While they are there, they attend a training camp to practice skills that might be helpful in the arena. At the training camp, there are 8 different stations such as camouflage, knife throwing, archery, plant identification, etc. At each of the 8 stations, tributes are scored on their skills from 1 to 10.
These 8 scores are combined into an overall score as follows:
Count the number of stations at which the tribute scored more than 5, demonstrating basic proficiency.
Count the number of stations at which the tribute scored more than 8, demonstrating expertise.
Add these counts together, capping the overall score at 12. This means that if the sum is larger than 12, the tribute earns the maximum possible score of 12.
Overall scores therefore range from 0 to 12. Which of the following functions takes as input an array containing a tribute’s 8 scores from the stations and correctly outputs their overall score? Select all that apply.
Hint: In Python, True + True evaluates
to 2.
def function1(stations):
overall = 0
for score in stations:
if score > 5:
overall = overall + 1
if score > 8:
overall = overall + 1
if overall >= 12:
return 12
return overalldef function2(stations):
overall = 0
for score in stations:
if score > 5:
overall = overall + 1
elif score > 8:
overall = overall + 2
return min(overall, 12)def function3(stations):
overall = 0
for i in np.arange(8):
if stations[i] > 8:
overall = overall + 2
elif stations[i] > 5:
overall = overall + 1
return min(overall, 12)def function4(stations):
overall = 0
for score in stations:
add = score > 5
add = (score > 8) + add
overall = overall + add
return min(overall, 12)def function5(stations):
return min(12, np.count_nonzero(stations > 5) + np.count_nonzero(stations > 8))Answer: Function 1, 3, 4, 5
The best way to go about this problem is individually check each function for correctness.
Function 1 correctly checks for scores > 5 and adds 1 for each valid instance. It then checks again if the same score is > 8 and adds another 1 to the total count. Finally there is a cap set to 12 to use if needed.
Function 2 uses the elif conditional so if score > 5,
it skips the score > 8 check. This means that scores > 8 only get
the plus 1 rather than the plus 2. Thus, this function is incorrect.
Function 3 iterates through all stations if the score > 8 it adds
2 otherwise (using elif), if the score is > 5, adds 1.
This is capped at 12 using the min function. Thus, this is a correct
implementation.
Function 4 is correct because it adds 1 point if the score is greater than 5 and then adds 1 more point if its also greater than 8. This is exactly what we are looking for in the problem statement.
Function 5 provides an elegant one-liner for the same problem using the count_nonzero function to count the number of scores greater than 5 and then adding that the to scores greater than 8. Together this does the same thing as adding 1 for each score between 5 and 8, and adding 2 for scores greater than 8.
The average score on this problem was 75%.
Trump’s administration set the reciprocal tariffs based on tariffs charged to the USA.
For each country in tariffs, the value in the
"Reciprocal Tariff" column is simply half of the value in
the "Tariffs Charged to USA" column, rounded
up to the next integer.
In addition, if the "Tariffs Charged to USA" is less
than 20 percent, then the
"Reciprocal Tariff" is set to 10 percent, so that no country’s reciprocal
tariff is ever less than 10
percent.
Fill in the blanks in the function reciprocate which
takes as input an integer representing the tariffs charged to the USA by
a country, and returns an integer representing the reciprocal tariff
that the US will impose on that country.
def reciprocate(charged):
half = int((charged + 1) / 2)
if __(a)__:
return __(b)__
else:
return __(c)__Answer (a): charged < 20 or
charged <= 20 or half < 10 or
half <= 10
Answer (b): 10
Answer (c): half
The average score on this problem was 79%.
Fill in the return statement of the function
reciprocate_2 which behaves the same as
reciprocate but is implemented differently. You may
not call the reciprocate function.
def reciprocate_2(charged):
return __(d)__Answer (d):
max(int((charged + 1)/2), 10)
The key to solving this question lies in understanding how Python’s max function works. The function takes an input called charged, adds 1 to it, and divides the result by 2, rounding down using int(). This gives a baseline number. However, since there’s a constraint that the result should never be less than 10, we use max to return the larger of the two values: either the computed number or 10. This ensures the final result is always at least 10.
The average score on this problem was 27%.
Define the variable ch as follows.
ch = tariffs.get("Tariffs Charged to USA")You want to check that reciprocate and
reciprocate_2 give the same outputs on all inputs in
ch. Write an expression that evaluates to True
if this is the case, and False otherwise.
Answer:
(ch.apply(reciprocate) == ch.apply(reciprocate_2)).sum() == 50
This question was a bit tricky! While it might seem sufficient to
check ch.apply(reciprocate) == ch.apply(reciprocate_2),
that actually returns a Series of boolean values—one for each row—rather
than a single True/False result. To properly verify that the functions
behave identically, you need to sum the True values and
compare that sum to the total number of rows in ch.
The average score on this problem was 39%.
The sums function takes in an array of numbers and
outputs the cumulative sum for each item in the array. The cumulative
sum for an element is the current element plus the sum of all the
previous elements in the array.
For example:
>>> sums(np.array([1, 2, 3, 4, 5]))
array([1, 3, 6, 10, 15])
>>> sums(np.array([100, 1, 1]))
array([100, 101, 102])The incomplete definition of sums is shown below.
def sums(arr):
res = _________
(a)
res = np.append(res, arr[0])
for i in _________:
(b)
res = np.append(res, _________)
(c)
return resFill in blank (a).
Answer: np.array([]) or
[]
res is the list in which we’ll be storing each
cumulative sum. Thus we start by initializing res to an
empty array or list.
The average score on this problem was 100%.
Fill in blank (b).
Answer: range(1, len(arr)) or
np.arange(1, len(arr))
We’re trying to loop through the indices of arr and
calculate the cumulative sum corresponding to each entry. To access each
index in sequential order, we simply use range() or
np.arange(). However, notice that we have already appended
the first entry of arr to res on line 3 of the
code snippet. (Note that the first entry of arr is the same
as the first cumulative sum.) Thus the lower bound of
range() (or np.arange()) actually starts at 1,
not 0. The upper bound is still len(arr) as usual.
The average score on this problem was 64%.
Fill in blank (c).
Answer: res[i - 1] + arr[i] or
sum(arr[:i + 1])
Looking at the syntax of the problem, the blank we have to fill
essentially requires us to calculate the current cumulative sum, since
the rest of line will already append the blank to res for
us. One way to think of a cumulative sum is to add the “current”
arr element to the previous cumulative sum, since the
previous cumulative sum encapsulates all the previous elements. Because
we have access to both of those values, we can easily represent it as
res[i - 1] + arr[i]. The second answer is more a more
direct approach. Because the cumulative sum is just the sum of all the
previous elements up to the current element, we can directly compute it
with sum(arr[:i + 1])
The average score on this problem was 71%.
In recent years, there has been an explosion of board games that teach computer programming skills, including CoderMindz, Robot Turtles, and Code Monkey Island. Many such games were made possible by Kickstarter crowdfunding campaigns.
Suppose that in one such game, players must prove their understanding
of functions and conditional statements by answering questions about the
function wham, defined below. Like players of this game,
you’ll also need to answer questions about this function.
1 def wham(a, b):
2 if a < b:
3 return a + 2
4 if a + 2 == b:
5 print(a + 3)
6 return b + 1
7 elif a - 1 > b:
8 print(a)
9 return a + 2
10 else:
11 return a + 1What is printed when we run print(wham(6, 4))?
Answer: 6 8
When we call wham(6, 4), a gets assigned to
the number 6 and b gets assigned to the number 4. In the
function we look at the first if-statement. The
if-statement is checking if a, 6, is less than
b, 4. We know 6 is not less than 4, so we skip this section
of code. Next we see the second if-statement which checks
if a, 6, plus 2 equals b, 4. We know 6 + 2 = 8, which is not equal to 4. We then
look at the elif-statement which asks if a, 6,
minus 1 is greater than b, 4. This is True! 6 - 1 = 5 and 5 > 4. So we
print(a), which will spit out 6 and then we will
return a + 2. a + 2 is 6 + 2. This means the function
wham will print 6 and return 8.
The average score on this problem was 81%.
Give an example of a pair of integers a and
b such that wham(a, b) returns
a + 1.
Answer: Any pair of integers a,
b with a = b or with
a = b + 1
The desired output is a + 1. So we want to look at the
function wham and see which condition is necessary to get
the output a + 1. It turns out that this can be found in
the else-block, which means we need to find an
a and b that will not satisfy any of the
if or elif-statements.
If a = b, so for example a points to 4 and
b points to 4 then: a is not less than
b (4 < 4), a + 2 is not equal to
b (4 + 2 = 6 and 6 does
not equal 4), and a - 1 is not greater than b
(4 - 1= 3) and 3 is not greater than
4.
If a = b + 1 this means that a is greater
than b, so for example if b is 4 then
a is 5 (4 + 1 = 5). If we
look at the if-statements then a < b is not
true (5 is greater than 4), a + 2 == b is also not true
(5 + 2 = 7 and 7 does not equal 4), and
a - 1 > b is also not true (5
- 1 = 4 and 4 is equal not greater than 4). This means it will
trigger the else statement.
The average score on this problem was 94%.
Which of the following lines of code will never be executed, for any input?
3
6
9
11
Answer: 6
For this to happen: a + 2 == b then a must
be less than b by 2. However if a is less than
b it will trigger the first if-statement. This
means this second if-statement will never run, which means
that the return on line 6 never happens.
The average score on this problem was 79%.
In the game Spot It, players race to identify an object that appears on two different cards. Each card contains images of eight objects, and exactly one object is common to both cards.
Suppose the objects appearing on each card are stored in an array,
and our task is to find the object that appears on both cards. Complete
the function find_match that takes as input two arrays of 8
objects each, with one object in common, and returns the name of the
object in both arrays.
For example, suppose we have two arrays defined as follows.
objects1 = np.array(["dragon", "spider", "car", "water droplet", "spiderweb", "candle", "ice cube", "ladybug"])
objects2 = np.array(["zebra", "lock", "dinosaur", "eye", "fire", "shamrock", "spider", "carrot"])Then find_match(objects1, objects2) should evaluate to
"spider". Your function must include a for loop, and it
must take at most three lines of code (not counting the
line with def).
Answer:
def find_match(array1, array2):
for obj in array1:
if obj in array2:
return objWe first need to define the function find_match(). We
can gather since we are feeding in two groups of objects we are giving
find_match() two parameters, which we have called
array1 and array2. The next step is utilizing
a for-loop. We want to look at all the objects inside of
array1 and then check using an if-statement if
that object exists in array2. If it does, we can stop the
loop and return the object!
The average score on this problem was 67%.
Now suppose the objects appearing on each card are stored in a
DataFrame with 8 rows and one column called "object".
Complete the function find_match_again that takes as input
two such DataFrames with one object in common and returns the nameof the
object in both DataFrames.
Your function may not call the previous function
find_match, and it must take exactly one line of
code (not counting the line with def).
Answer:
def find_match_again(df1, df2)
return df1.merge(df2, on = “object”).get(“object”).iloc[0]Once again we need to define our function and then have two
parameters for the two DataFrames. Recall the method
.merge() which will combine two DataFrames and only give us
the elements that are shared. The directions tell us that both
DataFrames have a single column called “object”. Since we
want to combine the DataFrames on that column we do have:
df1.merge(df2, on = “object”). Once we have merged the
DataFrames we should have only 1 row with the index and the column
“object”. To isolate the element inside of this DataFrame
we can first get a Series by doing .get(“object”) and then
do .iloc[0] to get the element inside of the Series.
The average score on this problem was 46%.
Storm forecasters are very interested in the direction in which a
tropical storm moves. This direction of movement can be determined by
looking at two consecutive rows in storms that correspond
to the same storm.
The function direction takes as input four values: the
latitude and longitude of a data entry for one storm, and the latitude
and longitude of the next data entry for that same storm. The function
should return the direction in which the storm moved in the period of
time between the two data entries. The return value should be one of the
following strings:
"NE" for Northeastern movement,"NW" for Northwestern movement,"SW" for Southwestern movement, or"SE" for Southeastern movement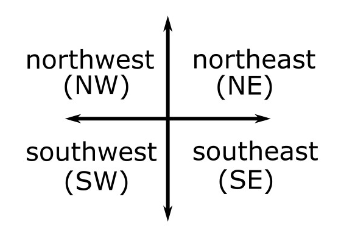
For example, direction(23.1, 75.1, 23.4, 75.7) should
return "NW". If the storm happened to move
directly North, South, East, or West, or if the storm did not
move at all, the function may return any one of "NE",
"NW", "SW", or "SE". Fill in the
blanks in the function direction below. It may help to
refer to the images on Page 5.
def direction(old_lat, old_long, new_lat, new_long):
if old_lat > new_lat and old_long > new_long:
return ____(a)____
elif old_lat < new_lat and old_long < new_long:
return ____(b)____
elif old_lat > new_lat:
return ____(c)____
else:
return ____(d)____What goes in blank (a)?
"NE"
"NW"
"SW"
"SE"
Answer: "SE"
According to the given example that
direction(23.1, 75.1, 23.4, 75.7) should return
"NW", we learn that having an old_lat <
new_lat (in the example: 23.1
< 23.4) causes for the storm to move North and that having a
old_long < new_long (in the example: 75.1 < 75.7) causes for the storm to move
West. This tells us if old_lat > new_lat
then the storm will move South, the opposite direction of North, and if
old_long > new_long then the storm will
move East, the opposite direction of West.
The if statement is looking for the direction where
(old_lat > new_lat and
old_long > new_long), so from above we can
tell it is moving Southeast. Remember both conditions must be satisfied
for this if statement to execute.
The average score on this problem was 73%.
What goes in blank (b)?
"NE"
"NW"
"SW"
"SE"
Answer: "NW"
Recall from the previous section the logic that:
old_lat < new_latold_lat > new_latold_long > new_longold_long < new_longThis means we are looking for the directions that satisfy the
elif statement: old_lat < new_lat and
old_long < new_long. Looking at our logic the statement
is satisfied by the direction Northwest.
The average score on this problem was 79%.
What goes in blank (c)?
"NE"
"NW"
"SW"
"SE"
Answer: "SW"
We know the answers cannot be 'SE' or 'NW'
because the if statement and elif statement above the one we are
currently working in will catch those. This tells us we are either
working with 'SW' or 'NE'. From the logic we
established in the previous subparts we know when 'old_lat'
> 'new_lat' we know the storm is going in the Southern
direction. This means the only possible answer is 'SW'.
The average score on this problem was 65%.
What goes in blank (d)?
"NE"
"NW"
"SW"
"SE"
Answer: "NE"
The only option we have left is 'NE'. Remember than
Python if statements will run every single if, and if none
of them are triggered then it will move to the elif
statements, and if none of those are triggered then it will finally run
the else statement. That means whatever direction not used
in parts a, b, and c needs to be used here.
The average score on this problem was 61%.
The most famous Hurricane Katrina took place in August, 2005. The
DataFrame katrina_05 contains just the rows of
storms corresponding to this hurricane, which we’ll call
Katrina’05.
Fill in the blanks in the code below so that
direction_array evaluates to an array of directions (each
of which is"NE", "NW", "SW", or
"SE") representing the movement of Katrina ’05 between each
pair of consecutive data entries in katrina_05.
direction_array = np.array([])
for i in np.arange(1, ____(a)____):
w = katrina_05.get("Latitude").____(b)____
x = katrina_05.get("Longitude").____(c)____
y = katrina_05.get("Latitude").____(d)____
z = katrina_05.get("Longitude").____(e)____
direction_array = np.append(direction_array, direction(w, x, y, z))What goes in blank (a)?
Answer: katrina_05.shape[0]
In this line of code we want to go through the entire Katrina’05
DataFrame. We are provided the inclusive start, but we need to find the
exclusive stop, which would be the number of rows in the DataFrame.
katrina_05.shape[0] takes the DataFrame, finds the shape,
which is represented by: (rows, columns), and then isolates
the rows in the first index.
The average score on this problem was 46%.
What goes in blank (b)?
Answer: iloc[i-1]
In this line of code we want to find the latitude of the row we are
in. The whole line of code:
katarina_05.get("Latitude").iloc[i-1] isolates the column
'Latitude' and uses iloc, which is a purely
integer-location based indexing function, to select the element at
position i-1. The reason we are doing i-1 is
because the for loop started an np.array at 1. For example,
if we wanted the latitude at index 0 we would need to do
iloc[1-1] to get the equivalent iloc[0].
The average score on this problem was 37%.
What goes in blank (c)?
Answer: iloc[i-1]
Similarily to part b, this line of code will find the longitude of
the row we are in. The whole line of code:
katarina_05.get("Longitude").iloc[i-1] isolates the column
'Longitude' and uses iloc, which is a purely
integer-location based indexing function, to select the element at
position i-1. The reason we are doing i-1 is
because the for loop started an np.array at 1.
The average score on this problem was 36%.
What goes in blank (d)?
Answer: iloc[i]
Now we are trying to find the “next” latitude, which will be the next
coordinate point that the storm Katrina moved to. This
means we want to find the latitude after the one we
found in part b. The whole line of code:
katarina_05.get("Latitude").iloc[i] isolates the
"Latitude" column, and uses iloc to choose the
element at position i. Recall, the for loop starts at 1, so
it will always be the “next” element comparatively to part b, where we
substracted 1.
The average score on this problem was 37%.
What goes in blank (e)?
Answer: iloc[i]
Similarily to part d, we are trying to find the “next” longitude,
which will be the next coordinate point that the storm
Katarina moved to. This means we want to find the longitude
after the one we found in part c. The whole line of
code: katarina_05.get("Longitude").iloc[i] isolates the
column 'Longitude' and uses iloc to choose the
element at position i. Recall, the for loop starts at 1, so
it will always be the “next” element comparitively to part c, where we
substracted 1.
The average score on this problem was 37%.
Now we want to use direction_array to find the number of
times that Katrina ’05 changed directions, or moved in a different
direction than it was moving immediately prior. For example, if
direction_array contained values "NW",
"NE", "NE", "NE",
"NW", we would say that there were two direction changes
(once from "NW" to "NE", and another from
"NE" to "NW"). Fill in the blanks so that
direction_changes evaluates to the number of times that
Katrina ’05 changed directions.
direction_changes = 0
for j in ____(a)____:
if ____(b)____:
direction_changes = direction_changes + 1What goes in blank (a)?
Answer:
np.arange(1, len(direction_array))
We want the for loop to execute the length of the given
direction_array because we compare all of the directions
inside of it. The line of code:
np.arange(1, len(direction_array)) will create an array
that is as large as the direction_array, which allows us to
use j to access different indexes inside of
direction_array.
The average score on this problem was 36%.
What goes in blank (b)?
Answer:
direction_array[j] != direction_array[j-1]
We want to increase direction_changes whenever there is
a switch between directions. This means we want to see if
direction_array[j] is not equal to
direction_array[j-1].
It is important to look at how the for loop is running
because it starts at 1 and ends at len(direction_array) - 1
(this is because np.arange has an exclusive stop). Let’s
say we wanted to compare the direction at index 5 and index 4. We can
easily get the element at index 5 by doing
direction_array[j] and then get the element at index 4 by
doing direction_array[j-1]. We can then check if they are
not equal to each other by using the !=
operation.
When the if statement activates it will then update the
direction_changes
The average score on this problem was 64%.
There are 34 rows in katrina_05. Based on this
information alone, what is the maxi- mum possible value of
direction_changes?
Answer: 32
Note: The maximum amount of direction changes would mean that every other direction would be different from each other.
It is also important to remember what we are feeding
into direction_changes. We are feeding in the output from
direction_array from Problem 7. Due to the
for-loops throughout this section we can see the maximum
amount of changes by 2. Once in direction_array and once in
direction_changes.
For a more visual explanation, let’s imagine katrina_05
has these values:
[(7, 3), (6, 4), (9, 2), (8, 7), (3, 5)]
We would then feed this into Problem 7’s direction_array
to get an array that looks like this:
["NE", "SW", "SE", "NW"]
Finally, we will feed this array into direction_changes.
We can see that there are three changes: one from "NE" to
"SW", one from "SW" to "SE", and
one from "SE" to "NW".
This means that the maximum amount of direction_changes
is 34-1-1 = 32. We subtract 1 for each
step in the process because we lose a value due to the
for-loops.
The average score on this problem was 36%.
When someone is ready to make an accusation, they make a statement such as:
“It was Miss Scarlett with the dagger in the study"
While the suspect, weapon, and room may be different, an accusation will always have this form:
“It was ______ with the ______ in the ______"
Suppose the array words is defined as follows (note the
spaces).
words = np.array(["It was ", " with the ", " in the "])Suppose another array called answers has been defined.
answers contains three elements: the name of the suspect,
weapon, and room that we would like to use in our accusation, in that
order. Using words and answers, complete the
for-loop below so that accusation is a string,
formatted as above, that represents our accusation.
accusation = ""
for i in ___(a)___:
accusation = ___(b)___What goes in blank (a)?
Answer: [0, 1, 2]
answers could potentially look like this array
np.array(['Mr. Green', 'knife', 'kitchen']). We want
accusation to be the following: “It was Mr. Green
with the knife in the kitchen” where the
underline represent the string from the words array and the
nonunderlined parts represent the string from the answers
array. In the for loop, we want to iterate through words and answers
simultaneously, so we can use [0, 1, 2] to represent the
indices of each array we will be iterating through.
The average score on this problem was 52%.
What goes in blank (b)?
Answer:
accusation + words[i] + answers[i]
We are performing string concatenation here. Using the example from
above, we want to add to the string accusation in order of
accusation, words, answer. After
all, we want “It was” before “Mr. Green”.
The average score on this problem was 56%.
Use the function defined below to answer the questions on the right.
def discount(duration, price):
if duration > 6:
price = price * 0.9
if duration > 4:
price = price * 0.95
elif duration > 3:
price = price * 0.98
else:
price = price * 0.99
price = price - 5
return priceWhat is the output of discount(7, 100)?
100 * 0.9 * 0.95 * 0.98 - 5
100 * 0.9 * 0.95 - 5
100 * 0.9 - 5
100 * 0.9
Answer: Option 2
The average score on this problem was 72%.
Find x and y such that
discount(x, y) evaluates to 97 * 0.98 - 5.
Answer (x): anything greater than 3 and
less than or equal to 4
The average score on this problem was 95%.
Answer (y): 97
The average score on this problem was 95%.