← return to practice.dsc10.com
Below are practice problems tagged for Lecture 4 (rendered directly from the original exam/quiz sources).
Which of these would it make sense to use as the index of
flights?
'DATE'
'FLIGHT'
'FROM'
'TO'
None of these are good choices for the index
Answer: None of these are good choices for the index
When choosing an index, we have to make sure that the index is different for each row of the DataFrame. The index in this case should uniquely identify the flight.
'DATE'does not uniquely identify a flight because there
are many different flights in a single day. 'FLIGHT' does
not uniquely identify a flight because airlines reuse flight numbers on
a daily basis, as we are told in the data description. Neither
'FROM' nor 'TO' uniquely identifies a flight,
as there are many flights each day that depart from each airport and
arrive at each airport.
Therefore, there is no single column that’s sufficient to uniquely
identify a flight, but if we could use multiple columns to create what’s
called a multi-index, we’d probably want to use 'DATE' and
'FLIGHT' because each row of our DataFrame should have a
unique pair of values in these columns. That’s because airlines don’t
reuse flight numbers within a single day.
The average score on this problem was 57%.
What type of variable is 'FLIGHT'?
Categorical
Numerical
Answer: Categorical
'FLIGHT' is a categorical variable because it doesn’t
make sense to do arithmetic with the values in the 'FLIGHT'
column. 'FLIGHT' is just a label for each flight, and the
fact that it includes some numbers does not make it numerical. We could
have just as well used letter codes to distinguish flights.
The average score on this problem was 98%.
Fill in the blanks below so that the result is a DataFrame with the
same columns as flights plus a new column,
'SPEED', containing the average speed of each flight, in
miles per hour.
flights.__(a)__(SPEED=__(b)__)What goes in blank (a)?
groupby
assign
rename
drop
merge
Answer: assign
We want to add a new column, so we must use assign. We
can also tell that the answer will be assign because it’s
the only DataFrame method that takes an input of the form
SPEED=___. Remember that when using assign, we get to call
the new column anything we want, and we don’t use quotes around its
name.
The average score on this problem was 100%.
What goes in blank (b)?
Answer:
(flights.get('DIST') / flights.get('HOURS'))
In this blank, we’ll need a Series or array containing the average speed of each flight, in miles per hour.
To calculate the average speed of an individual flight in miles per
hour, we’d simply divide the total number of miles by the total amount
of time in hours. For example, a flight that travels 500 miles in one
hour travels at 500 miles per hour. Note that this is an
average speed; at some points of the journey, the plane may
have been moving faster than this speed, at other times slower. Because
we are calculating an average speed for the whole trip by simply
dividing, we don’t need to use .mean().
Once we know how to calculate the average speed for an individual
flight, we can do the same operation on each flight all at once using
Series arithmetic. flights.get('DIST') is a Series
containing the distances of each flight, and
flights.get('HOURS') is a Series containing the times of
each flight, in the same order. When we divide these two Series,
corresponding entries are divided and the result is a Series of average
speeds for each flight, as desired.
The average score on this problem was 93%.
Suppose students is a DataFrame of all students who took
DSC 10 last quarter. students has one row per student,
where:
The index contains students’ PIDs as strings starting with
"A".
The "Overall" column contains students’ overall
percentage grades as floats.
The "Animal" column contains students’ favorite
animals as strings.
What type is students.get("Overall")? If this expression
errors, select “this errors."
float
string
array
Series
this errors
Answer: Series
The average score on this problem was 73%.
What type is students.get("PID")? If this expression
errors, select “this errors."
float
string
array
Series
this errors
Answer: this errors
The average score on this problem was 67%.
Vanessa is one student who took DSC 10 last quarter. Her PID is A12345678, she earned the sixth-highest overall percentage grade in the class, and her favorite animal is the giraffe.
Supposing that students is already sorted by
"Overall" in descending order, fill in the
blanks so that animal_one and animal_two
both evaluate to "giraffe".
animal_one = students.get(__(x)__).loc[__(y)__]
animal_two = students.get(__(x)__).iloc[__(z)__]Answer:
x: "Animal"y: "A12345678"z: 5
The average score on this problem was 69%.
If students wasn’t already sorted by
"Overall" in descending order, which of your answers would
need to change?
Neither y nor z would need to change
Both y and z would need to change
y only
z only
Answer: z only
The average score on this problem was 82%.
Notice that bookstore has an index of
"ISBN" and sales does not. Why is that?
There is no good reason. We could have set the index of
sales to "ISBN".
There can be two different books with the same
"ISBN".
"ISBN" is already being used as the index of
bookstore, so it shouldn’t also be used as the index of
sales.
The bookstore can sell multiple copies of the same book.
Answer: The bookstore can sell multiple copies of the same book.
In the sales DataFrame, each row represents an
individual sale, meaning multiple rows can have the same
"ISBN" if multiple copies of the same book are sold.
Therefore we can’t use it as the index because it is not a unique
identifier for rows of sales.
The average score on this problem was 87%.
Is "ISBN" a numerical or categorical variable?
numerical
categorical
Answer: categorical
Even though "ISBN" consists of numbers, it is used to
identify and categorize books rather than to quantify or measure
anything, thus it is categorical. It doesn’t make sense to compare ISBN
numbers like you would compare numbers on a number line, or to do
arithmetic with ISBN numbers.
The average score on this problem was 75%.
Which type of data visualization should be used to compare authors by median rating?
scatter plot
line plot
bar chart
histogram
Answer: bar chart
A bar chart is best, as it visualizes numerical values (median ratings) across discrete categories (authors).
The average score on this problem was 88%.
Which of the following columns would be an appropriate index for the
treat DataFrame?
"address"
"candy"
"neighborhood"
None of these.
Answer: None of these.
The index uniquely identifies each row of a DataFrame. As a result,
for a column to be a candidate for the index, it must not contain repeat
items. Since it is possible for an address to give out different types
of candy, values in "address" can show up multiple times.
Similarly, values in "candy" can also show up multiple
times as it will appear anytime a house gives it out. Finally, a
neighborhood has multiple houses, so if more than one of those houses
show up, that value in "neighborhood" will appear multiple
times. Since "address", "candy", and
"neighborhood" can potentially have repeat values, none of
them can be the index for treat.
The average score on this problem was 54%.
Which of the following expressions evaluate to
"M&M"? Select all that apply.
treat.get("candy").iloc[1]
treat.sort_values(by="candy", ascending = False).get("candy").iloc[1]
treat.sort_values(by="candy", ascending = False).get("candy").loc[1]
treat.set_index("candy").index[-1]
None of these.
Answer: treat.get("candy").iloc[1] and
treat.sort_values(by="candy", ascending = False).get("candy").loc[1]
Option 1:
treat.get("candy").iloc[1] gets the candy
column and then retrieves the value at index location 1,
which would be "M&M".
Option 2:
treat.sort_values(by="candy", ascending=False).get("candy").iloc[1]
sorts the candy column in descending order (alphabetically,
the last candy is at the top) and then retrieves the value at index
location 1 in the candy column. The entire
dataset is not shown, but in the given rows, the second-to-last candy
alphabetically is "Skittles", so we know that
"M&M" will not be the second-to-last alphabetical candy
in the full dataset.
Option 3:
treat.sort_values(by="candy", ascending=False).get("candy").loc[1]
is very similar to the last option; however, this time,
.loc[1] is used instead of .iloc[1]. This
means that instead of looking at the row in position 1
(second row) of the sorted DataFrame, we are finding the row with an
index label of 1. When the rows are sorted by
candy in descending order, the index labels remain with
their original rows, so the "M&M" row is retrieved when
we search for the index label 1.
Option 4:
treat.set_index("candy").index[-1] sets the index to the
candy column and then retrieves the last element in the
index (candy). The entire dataset is not shown, but in the
given rows, the last value would be "Skittles" and not
"M&M". The last value of the full dataset could be
"M&M", but since we are not sure, this option is not
selected.
The average score on this problem was 66%.
The DataFrame finding_nemo contains information about
characters in the movie Finding Nemo. Each row represents a
character, and the columns include:
"Name" (str): the unique name of the character (ex.
"Nemo", "Dory")
"Species" (str): the species of the character (ex.
"clownfish", "blue tang")
There is one character in finding_nemo named
"Bruce". Which of the following lines of code evaluates to
Bruce’s species?
finding_nemo.get("Species").loc["Bruce"]
finding_nemo.get("Species").iloc["Bruce"]
finding_nemo.get("Species").loc["Bruce"].iloc[0]
finding_nemo.set_index("Name").get("Species").loc["Bruce"]
finding_nemo.set_index("Name").get("Species").iloc["Bruce"]
finding_nemo.set_index("Name").get("Species").loc["Bruce"].iloc[0]
Answer:
finding_nemo.set_index("Name").get("Species").loc["Bruce"]
The average score on this problem was 80%.
For the opening trailer, your boss needs you to find out two facts about Super Smash Brothers history. Write one line of Python code that evaluates to each quantity below.
The median origin "Year" of all fighters in
smash.
Answer: smash.get("Year").median()
The average score on this problem was 80%.
The name of the fighter with the earliest origin "Year"
(or in the case of a tie, any fighter from the earliest origin
"Year").
Answer:
smash.sort_values(by = "Year").get("Name").iloc[0] OR
smash.set_index("Name").sort_values(by = "Year").index[0]
The average score on this problem was 63%.
Complete the expression below so that it evaluates to the name of the product for which the average assembly cost per package is lowest.
(ikea.assign(assembly_per_package = ___(a)___)
.sort_values(by='assembly_per_package').___(b)___)What goes in blank (a)?
Answer:
ikea.get('assembly_cost')/ikea.get('packages')
This column, as its name suggests, contains the average assembly cost per package, obtained by dividing the total cost of each product by the number of packages that product comes in. This code uses the fact that arithmetic operations between two Series happens element-wise.
The average score on this problem was 91%.
What goes in blank (b)?
Answer: get('product').iloc[0]
After adding the 'assembly_per_package' column and
sorting by that column in the default ascending order, the product with
the lowest 'assembly_per_package' will be in the very first
row. To access the name of that product, we need to get the
column containing product names and use iloc to access an
element of that Series by integer position.
The average score on this problem was 66%.
Which of the following is a valid reason not to set
the index of sungod to 'Artist'?
Select all correct answers.
Two different artists have the same name.
An artist performed at Sun God in more than one year.
Several different artists performed at Sun God in the same year.
Many different artists share the same value of
'Appearance_Order'.
None of the above.
Answer: Two different artists have the same name., An artist performed at Sun God in more than one year.
For this question, it is crucial to know that an index should not
contain duplicate values, so we need to consider reasons why
'Artist' might contain two values that are the same. Let’s
go through the answer choices in order.
For the first option, if two different artists had the same name,
this would lead to duplicate values in the 'Artist' column.
Therefore, this is a valid reson not to index sungod by
'Artist'.
For the second option, if one artist performed at Sun God in more
than one year, their name would appear multiple times in the
'Artist' column, once for each year they performed. This
would also be a valid reason not to index sungod by
'Artist'.
For the third option, if several different artists performed at Sun
God in the same year, that would not necessarily create duplicates in
the 'Artist' column, unless of course two of the artists
had the same name, which we’ve already addressed in the first answer
choice. This is not a valid reason to avoid indexing sungod
by 'Artist'.
For the last answer choice, if many different artists share the same
value of 'Appearance_Order', this would not create
duplicates in the 'Artist' column. Therefore, this is also
not a valid reason to avoid indexing sungod by
'Artist'.
The average score on this problem was 83%.
Suppose in a new cell, we type the following.
sungod.sort_values(by='Year')After we run that cell, we type the following in a second cell.
sungod.get('Artist').iloc[0]What is the output when we run the second cell? Note that the first Sun God festival was held in 1983.
'Blues Traveler'
The artist who appeared on stage first in 1983.
An artist who appeared in 1983, but not necessarily the one who appeared first.
Not enough information to tell.
Answer: 'Blues Traveler'
In the first cell, although we seem to be sorting sungod
by 'Year', we aren’t actually changing the DataFrame
sungod at all because we don’t save the sorted DataFrame.
Remember that DataFrame methods don’t actually change the underlying
DataFrame unless you explicitly make that happen by saving the output as
the name of the DataFrame. So the first 'Artist' name will
still be 'Blues Traveler'.
Suppose we had saved the sorted DataFrame as in the code below.
sungod = sungod.sort_values(by='Year')
sungod.get('Artist').iloc[0]In this case, the output would be the name of an artist who appeared in 1983, but not necessarily the one who appeared first. There will be several artists associated with the year 1983, and we don’t know which of them will be first in the sorted DataFrame.
The average score on this problem was 12%.
For each expression below, determine the data type of the output and the value of the expression, if possible. If there is not enough information to determine the expression’s value, write “Unknown” in the corresponding blank.
apts.get("Rent").iloc[43] * 4 / 2
Answer:
We know that all values in the column Rent are
ints. So, when we call .iloc[43] on this
column (which grabs the 44th entry in the column), we know the result
will be an int. We then perform some multiplication and
division with this value. Importantly, when we divide an
int, the type is automatically changed to a
float, so the type of the final output will be a
float. Since we do not explicitly know what the 44th entry
in the Rent column is, the exact value of this
float is unknown to us.
The average score on this problem was 77%.
apts.get("Neighborhood").iloc[2][-3]
Answer:
This code takes the third entry (the entry at index 2) from the
Neighborhood column of apts, which is a
str, and it takes the third to last letter of that string.
The third entry in the Neighborhood column is
'Midway', and the third to last letter of
'Midway' is 'w'. So, our result is a
string with value w.
The average score on this problem was 73%.
(apts.get("Laundry") + 5).max()
Answer:
This code deals with the Laundry column of
apts, which is a Series of Trues and
Falses. One property of Trues and
Falses is that they are also interpreted by Python as ones
and zeroes. So, the code (apts.get("Laundry") + 5).max()
adds five to each of the ones and zeroes in this column, and then takes
the maximum value from the column, which would be an int of
value 6.
The average score on this problem was 69%.
apts.get("Complex").str.contains("Verde")
Answer:
This code takes the column (series) "Complex" and
returns a new series of True and False values.
Each True in the new column is a result of an entry in the
"Complex" column containing "Verde". Each
False in the new column is a result of an entry in the
"Complex" column failing to contain "Verde".
Since we are not given the entirety of the "Complex"
column, the exact value of the resulting series is unknown to us.
The average score on this problem was 64%.
apts.get("Sqft").median() > 1000
Answer:
This code finds the median of the column (series) "Sqft"
and compares it to a value of 1000, resulting in a bool
value of True or False. Since we do not know
the median of the "Sqft" column, the exact value of the
resulting code is unknown to us.
The average score on this problem was 87%.
The first contact in contacts is your friend Calvin, who
has an interesting phone number, with all the digits in descending
order: 987-654-3210. Fill in the blanks below so that each expression
evaluates to the sum of the digits in Calvin’s phone number.
contacts.get("Phone").apply(sum_phone).iloc[___(a)___]Answer: 0
(a) should be filled with 0 because
.iloc[0] refers to the first item in a Series, which
corresponds to Calvin.
The average score on this problem was 89%.
sum_phone(contacts.get("Phone").loc[___(b)___])Answer: "Calvin"
(b) should be filled with "Calvin" because
.loc[] accesses an element of Series by its row label. In
this case, "Calvin" is the index label of the Series
element that contains Calvin’s phone number.
The average score on this problem was 84%.
np.arange(__(c)__,__(d)__,__(e)__).sum() Answer:
(c): 0 or alternate solution 9
(d): 10 or alternate solution
-1
(e): 1 or alternate solution
-1
The expression uses np.arange() to generate a range of
numbers and then sums them up. From the problem, we can see that
Calvin’s phone number includes every digit from 9 to 0, so summing this
is equivalent to summing the digits from 9 down to 0 or from 0 to 9.
np.arange(0, 10, 1) generates [0, 1, 2, 3, 4, 5, 6, 7,
8, 9]. Alternatively, using the numbers in descending order (like the
digits in Calvin’s phone number): np.arange(9, -1, -1)
generates [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]. Both correctly sum up to
45.
The average score on this problem was 74%.
Suppose flower_data is a DataFrame with information on
different species of flowers, where:
The "species" column contains the name of the
species of flower, as a string. Each value in this column is
unique.
The "petals" column contains the average number of
petals of flowers of this species, as an int.
The "length" column contains the average stem length
of flowers of this species in inches, as a float.
One of these three columns is a good choice to use as the index of
this DataFrame. Write a line of code that sets this column as the index
of flower_data, and assigns the resulting DataFrame to the
variable flowers.
Answer:
flowers = flower_data.set_index("species")
The average score on this problem was 79%.
Important: The following questions will use
flowers instead of flower_data.
Which of the following expressions evaluates to a DataFrame that is
sorted by "petals" in descending order?
flowers.sort_values(by = "petals", ascending = True)
flowers.sort_values(by = "petals", ascending = False)
flowers.get("petals").sort_values(ascending = True)
flowers.get("petals").sort_values(ascending = False)
Answer: Option B
The average score on this problem was 83%.
Suppose that the 4th row of flowers corresponds to a
rare species of flower named "fire lily". Fill in the
blanks below so that both of these expressions evaluate to the stem
length in inches of "fire lily".
i. flowers.get("length").loc[__(x)__]
ii. flowers.get("length").iloc[__(y)__]Answer: (x): "fire lily", (y):
3
The average score on this problem was 83%.
Suppose that the 3rd row of flowers corresponds to the
species "stinking corpse lily". Using the
flowers DataFrame and the string method
.split(), write an expression that evaluates to
"corpse".
Answer:
flowers.index[2].split(" ")[1]
The average score on this problem was 46%.
So far, we have seen one way that children have tickets entered into the reaping: they receive one ticket when they are 12 years old, and then each year thereafter, an additional ticket is added onto the previous year’s total. This means 13-year-olds have two tickets, 14-year-olds have three tickets, and so on. We’ll call these tickets age tickets.
In this problem only, we’ll consider another way that a child may choose to enter tickets into the reaping in addition to the mandatory age tickets. If a child wishes, they can guarantee food rations for their family members, including themselves, at the price of one ticket per person. We’ll call these tickets food tickets. Like age tickets, food tickets are compounded each year, adding onto last year’s total.
As an example, let’s calculate the number of tickets that Katniss Everdeen has entered into the drawing at the reaping. Katniss is 16 years old, and every year, she has bought food for 3 family members (herself, her mother, and her sister Prim). This means:
At age 12, Katniss had one age ticket and three food tickets, making 4 tickets total.
At age 13, Katniss had one age ticket and three food tickets in addition to the 4 tickets from the year before, making 8 tickets total.
At age 14, Katniss again had one age ticket and three food tickets in addition to the 8 tickets from the year before, making 12 tickets total.
This pattern continues, and by the time Katniss is 16, she has 20 tickets.
In other words, Katniss had 4
tickets entered when she was 12 years,
and 4 more with each passing year. The
array np.arange(4, 24, 4) contains the number of tickets
Katniss entered each year, starting at age 12, up to and including her current age of
16 years old.
Fill in the blanks below to define the function
tix_array which takes in a child’s current age
between 12 and 18 (inclusive) and a number of family
members, k. The function returns an array similar Katniss’s
array above, representing the number of tickets they entered into the
reaping each year since they were 12
years old, assuming that they buy food for their whole family every
year.
Tip: tix_array(16, 3) should be the
same as the array np.arange(4, 24, 4).
def tix_array(age, k):
return np.arange(__(a)__, __(b)__, __(c)__)Answer:
(a): k + 1
(b): (ages - 10) * (k + 1)
(c): k + 1
At age 12 each kid gets 1 ticket for their age and k
food tickets; therefore, the starting value of our list must be must be
at k + 1 because that’s how many tickets they get when they
first enter. Next, we want the list to go up to the kid’s current age.
This means we can stop at (age - 10) * (k + 1) to cover all
of the years beginning from age 12 all the way till their current age.
Finally, each year the kid adds the same number of tickets one for their
increase in age and another k for food. Thus, the step is
k + 1.
The average score on this problem was 52%.
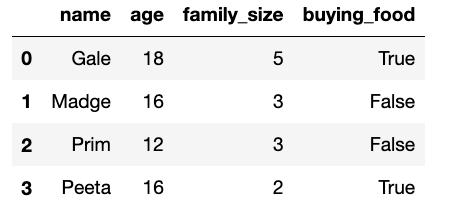
The DataFrame reaping contains information on the
children of District 12 between the ages of 12 and 18.
For each child, we have their "name", "age",
"family_size" which includes themselves, and a boolean
variable "buying_food". A value of True means
the child always buys food for their entire family, and
False means the child never buys food for anyone. The first
few rows of reaping are shown below, but there are many
more rows than pictured.
Fill in the blanks in the code below to add a new column,
"tickets", to reaping that contains the number
of tickets that the child will have entered into the drawing in the
current year.
Hint: In Python, True is treated as
1 and False is treated as
0 when doing arithmetic!
tickets_per_year = __(d)__ * __(e)__ + 1
current_tickets = tickets_per_year * (__(f)__)
reaping = reaping.assign(tickets = current_tickets)Answer:
(d): reaping.get("buying_food")
(e): reaping.get("family_size")
(f): reaping.get("age") - 11
We use the "buying_food" column to extract whether a
child chose to get extra food rations. This value consists of
bool values, and because of the way booleans are encoded in
python we can use this column as part of the math.
We use "family_size" because the child needs one food
ticket per each one of their family members. Multiplying it by
"buying_food" column from the previous part gives the
correct number of food tickets per year which is either the full family
size (if they are buying food) or 0 (if they are not buying food).
Finally we can use our shortcut to calculate the number of years a
child has been entering tickets, our shortcut being subtracting the age
of each child found in the "age" column by 11.
The average score on this problem was 61%.
For this subpart, assume that the tix_array function was
defined correctly in part (a), and that
the "tickets" column was added correctly to the
reaping DataFrame in part (b). Fill in the blanks in the code below so
that the following expression evaluates to True.
reaping.get("tickets").iloc[7] == tix_array(__(g)__, __(h)__)[-1]Answer:
(g): reaping.get("age").iloc[7]
(h): reaping.get("family_size").iloc[7]
The left side of the equation looks to access the number of tickets associated with the 8th child. To check this using the tix_array function we need to use the current age of the 8th child and the family size of the 8th child as inputs. We can get these values by extracting them from their respective columns.
The average score on this problem was 85%.
Which column of kart would work best as the index?
"Ranking"
"Team"
"Division"
"Total Points"
Answer: "Team"
Recall a choice for a good index would be a column wherein the values
would act as a unique identifier for a particular observation. The only
column that suits this description would be “Team” since
each row represents a unique team.
The average score on this problem was 86%.
Write a line of python code that sets the index of kart
to the column that you identified in part (1).
Answer:
kart = kart.set_index("Team")
We use set_index(“Team”) to set the DataFrame’s index to
“Team” and set this equal to kart to save this
change.
The average score on this problem was 81%.
Fill in the blanks below to complete the implementation of the
function division_to _int, which takes in a string,
division, the name of a division, and returns the
division’s number as an int. Example behavior is given
below.
>>> division_to_int("Division 1")
1
>>> division_to_int("Division 2")
2def division_to_int(division):
__(i)__ __(ii)__(division.__(iii)__[__(iv)__])Answer:
returnintsplit() or
split(" ")-1 or 1Using the argument division, we just want to retrieve
the number. To accomplish this, we can use split() on the
division to separate the string in order to access the
number. Note that the default behavior of split() is to
split by the space.
The output of division.split() is now a list of
“Division” and the number. To retrieve the number in this
list, we can index for it with either -1 (since it is the last element
of the list) or 1 (since it is the second element in the list). Because
we want the output to be an integer type, we use int to
cast the value to an integer. Finally, to have the function output the
desired value, we start with a return statement.
The average score on this problem was 67%.
The average score on this problem was 71%.
The average score on this problem was 52%.
The average score on this problem was 52%.
Write a single line of code that applies
division_to_int to the existing "Division"
column, and updates the "Division" column in
kart.
Answer:
kart.assign(Division=kart.get("Division").apply(division_to_int))
First let’s start by getting the information we want for the new
column. We get the column for transformation with
kart.get(“Division”) and use
.apply(division_to_int) in order to apply the function to
this column. In order to update this transformed Series as a column
“Division”, we use the .assign method on the
DataFrame and set the transformed Series to the column name
“Division”. Note that when using .assign to
add a column and the chosen column name already exists,
.assign will update the information in this column with the
new input information.
The average score on this problem was 81%.
For the rest of this exam, assume that the changes above have not
been made and that kart is the same DataFrame that was
described on the attached information sheet.
Fill in the blanks so that the expression below evaluates to the
"University" of the lowest scoring Division 2 team over the
whole season.
kart[__(a)__].__(b)__(__(c)__).get("University").iloc[0]Answer:
kart.get("Division") == "Division 2"sort values"Total Points" or
by="Total Points"First we want to filter the DataFrame for only the Division 2 teams
using kart.get("Division") == "Division 2".
Since we are interested in the lowest scoring team in this division,
we want to use sort_values on the
"Total Points" column giving
sort_values(by= “Total Points”). Since we are retrieving
.iloc[0], i.e. the top row of the DataFrame, we do not have
to specify the order of ranking since the default behavior of
sort_values is ascending.
The average score on this problem was 74%.
The average score on this problem was 90%.
The average score on this problem was 86%.
The command .set_index can take as input one column, to
be used as the index, or a sequence of columns to be used as a nested
index (sometimes called a MultiIndex). A MultiIndex is the default
behavior of the dataframe returned by .groupby with multiple
columns.
You are given a dataframe called restaurants that contains information on a variety of local restaurants’ daily number of customers and daily income. There is a row for each restaurant for each date in a given five-year time period.
The columns of restaurants are 'name'
(str), 'year' (int),
'month' (int), 'day'
(int), 'num_diners' (int), and
'income' (float).
Assume that in our data set, there are not two different restaurants that go by the same name (chain restaurants, for example).
Which of the following would be the best way to set the index for this dataset?
restaurants.set_index('name')
restaurants.set_index(['year', 'month', 'day'])
restaurants.set_index(['name', 'year', 'month', 'day'])
Answer:
restaurants.set_index(['name', 'year', 'month', 'day'])
The correct answer is to create an index with the
'name', 'year', ‘month’, and
‘day’ columns. The question provides that there is a row
for each restaurant for each data in the five year span. Therefore, we
are interested in the granularity of a specific day (the day, the month,
and the year). In order to have this information available in this
index, we must set the index to be a multi index with columns
['name', 'year', 'month', 'day']. Looking at the other
options, simply looking at the 'name' column would not
account for the fact the dataframe contains daily data on customers and
income for each restaurant. Similarly, the second option of
['name', 'month', 'day'] would not account for the fact
that the data comes in a five year span so there will naturally be five
overlaps (one for each year) for each unique date that must be accounted
for.
The average score on this problem was 53%.
You are given a DataFrame called sports, indexed by
'Sport' containing one column,
'PlayersPerTeam'. The first few rows of the DataFrame are
shown below:
| Sport | PlayersPerTeam |
|---|---|
| baseball | 9 |
| basketball | 5 |
| field hockey | 11 |
Which of the following evaluates to
'basketball'?
sports.loc[1]
sports.iloc[1]
sports.index[1]
sports.get('Sport').iloc[1]
Answer: sports.index[1]
We are told that the DataFrame is indexed by 'Sport' and
'basketball' is one of the elements of the index. To access
an element of the index, we use .index to extract the index
and square brackets to extract an element at a certain position.
Therefore, sports.index[1] will evaluate to
'basketball'.
The first two answer choices attempt to use .loc or
.iloc directly on a DataFrame. We typically use
.loc or .iloc on a Series that results from
using .get on some column. Although we don’t typically do
it this way, it is possible to use .loc or
.iloc directly on a DataFrame, but doing so would produce
an entire row of the DataFrame. Since we want just one word,
'basketball', the first two answer choices must be
incorrect.
The last answer choice is incorrect because we can’t use
.get with the index, only with a column. The index is never
considered a column.
The average score on this problem was 88%.
Suppose you are given a DataFrame of employees for a given company.
The DataFrame, called employees, is indexed by
'employee_id' (string) with a column called
'years' (int) that contains the number of years each
employee has worked for the company.
Suppose that the code
employees.sort_values(by='years', ascending=False).index[0]outputs '2476'.
True or False: The number of years that employee 2476 has worked for the company is greater than the number of years that any other employee has worked for the company.
True
False
Answer: False
This is false because there could be other employees who worked at the company equally long as employee 2476.
The code says that when the employees DataFrame is
sorted in descending order of 'years', employee 2476 is in
the first row. There might, however, be a tie among several employees
for their value of 'years'. In that case, employee 2476 may
wind up in the first row of the sorted DataFrame, but we cannot say that
the number of years employee 2476 has worked for the company is greater
than the number of years that any other employee has worked for the
company.
If the statement had said greater than or equal to instead of greater than, the statement would have been true.
The average score on this problem was 29%.
What will be the output of the following code?
employees.assign(start=2021-employees.get('years'))
employees.sort_values(by='start').index.iloc[-1]the employee id of an employee who has worked there for the most years
the employee id of an employee who has worked there for the fewest years
an error message complaining about iloc[-1]
an error message complaining about something else
Answer: an error message complaining about something else
The problem is that the first line of code does not actually add a
new column to the employees DataFrame because the
expression is not saved. So the second line tries to sort by a column,
'start', that doesn’t exist in the employees
DataFrame and runs into an error when it can’t find a column by that
name.
This code also has a problem with iloc[-1], since
iloc cannot be used on the index, but since the problem
with the missing 'start' column is encountered first, that
will be the error message displayed.
The average score on this problem was 27%.
Which column would be an appropriate index for storms?
'Name'
'Date'
'Time'
'Latitude'
None of these
Answer: None of these.
An index should be unique. In this case 'Name',
'Date', 'Time', and 'Latitude'
have repetative values, which does not make them
unique. Remember 'Name' will be reused every six years,
multiple hurricanes could happen on the same date, time, or
latitude.
The average score on this problem was 69%.
Suppose there are n different storms included in
storms. Say we create a new DataFrame from
storms by adding a column called 'Duration'
that contains the number of minutes since the first data entry for that
storm, as an int. The first few rows of this new DataFrame
are shown below.
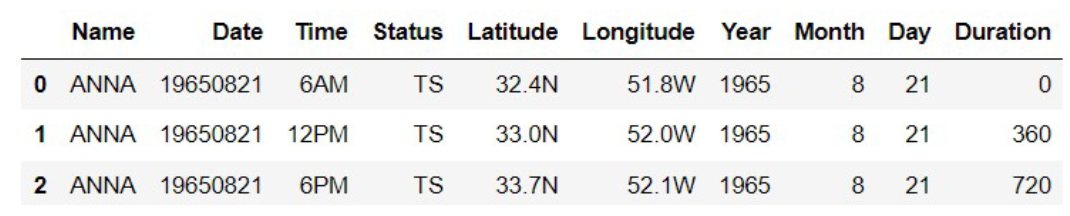
Next we sort this DataFrame in ascending order of
'Duration' and save the result as
storms_by_duration. Which of the following statements must
be true? Select all that apply.
The first n rows of storms_by_duration will
all correspond to different storms, because they will contain the first
reading from each storm in the data set.
The last n rows of storms_by_duration will
all correspond to different storms, because they will contain the last
reading from each storm in the data set.
storms_by_duration will contain exactly n rows.
len(storms_by_duration.take(np.arange(n)).get("Name").unique())
will evaluate to n.
Answer: “The first n rows of
storms_by_duration will all correspond to different storms,
because they will contain the first reading from each storm in the data
set.”
Let’s first analyze the directions. According to the directions, we
added the column 'Duration', so we know how long each storm
lasted. Then we sorted the DataFrame in ascending order, which will put
the storms with the shortest duration at the top.
Each row will be tied to a unique storm because each storm can only
have one minimum. This means storms_by_duration’s first
n rows will contain the shortest duration for each unique
storm, which corresponds to the first option.
Option 2: This is incorrect because even though the
DataFrame is sorted in ascending order it is possible for a storm to
have multiple close values in 'Duration', which does not
guarantee unique storms in the last n rows. For example if
you had the storm 'alice', which one time had a duration of
60 and the longest duration of 62. The values will be sorted such that
60 will come before 62, but they are within the last n
values of the DataFrame, causing 'alice' to appear
twice.
Option 3: This is incorrect because there can be
more than n rows. It is possible that a storm appears
multiple times. For example the storm Anna occurred three
different times on August 21, 1965 without sorting.
Option 4: This is incorrect. The code written will
take the first n rows of the table, get the names, and find
the number of unique named storms. Names are not unique, so it is
possible for the storms to share the same name. This can be seen in the
DataFrame example above.
The average score on this problem was 66%.
Which of the following columns would be an appropriate index for the
olympians DataFrame?
"Name"
"Sport"
"Team"
None of these.
Answer: None of these.
To decide what an appropriate index would be, we need to keep in mind
that in each row, the index should have a unique value – that is, we
want the index to uniquely identify rows of the DataFrame. In this case,
there will obviously be repeats in "team" and
"sport", since these will appear multiple times for each
Olympic event. Although the name is unique for each athlete, the same
athlete could compete in multiple Olympics (for example, Michael Phelps
competed in both 2008 and 2004). So, none of these options is a valid
index.
The average score on this problem was 74%.
Suppose fruits is a DataFrame of the fruits Ashley
bought at the grocery store, where:
The "fruit" column contains the name of the fruit,
as a string. All values in this column are distinct.
The "price" column contains the amount in dollars
spent on the fruit, as a float.
The "pounds" column contains the number of
pounds purchased, as an int.
Fill in the blanks below to add a new column to fruits
called "price_per_ounce" that contains the price per ounce
of each of the fruits in fruits. There are 16
ounces in a pound.
fruits = fruits.__(x)__(price_per_ounce = __(y)__ / __(z)__)Answer (x): assign
The average score on this problem was 71%.
Answer (y): fruits.get("price")
The average score on this problem was 67%.
Answer (z):
(fruits.get("pounds") * 16)
The average score on this problem was 43%.
Write a line of code that evaluates to the amount of money, in dollars, that Ashley spent on fruit at the grocery store.
Answer: fruits.get("price").sum() or
sum(fruits.get("price"))
The average score on this problem was 62%.
Fill in the blanks so that the expression below evaluates to the name of the fruit with the highest price per ounce.
(fruits.sort_values(by = "price_per_ounce", ascending = __(x)__)
.get(__(y)__).iloc[0])Answer (x): False
The average score on this problem was 87%.
Answer (y): "fruit"
The average score on this problem was 65%.
Assuming that "mango" is one of the fruits Ashley
bought, fill in the blanks so that the expression below evaluates to the
price per ounce of "mango".
fruits.__(x)__("fruit").get("price_per_ounce").__(y)__["mango"]Answer (x): set_index
The average score on this problem was 41%.
Answer (y): loc
The average score on this problem was 83%.
Which of the following columns would be an appropriate index for the
dining DataFrame?
"Dining Hall"
"Item"
"Price"
"Calories"
None of these.
Answer: None of these
None of the following columns would be an appropriate index since
they all possibly contain duplicates. We are told that each row
represents a single menu item available at one of the UCSD dining halls.
This means that each row represents a combination of both
"Dining Hall" and "Item" so no one column is
sufficient to uniquely identify a row. We can see this in the preview of
the first few rows of the DataFrame. There are multiple rows with the
same value in the "Dining Hall" column, and also multiple
rows with the same value in the "Item" column.
While "Price" and "Calories" could
be unique, it doesn’t make sense to refer to a row by its price or
number of calories. Further, we have no information that guarantees the
values in these columns are unique (they’re probably not).
The average score on this problem was 76%.
For each expression below, write the output that Python produces, or write error if the expression produces an error.
str(courses.take(np.arange(4)).shape[0]) * 2Answer: "44"
courses.take(np.arange(4)) keeps the first four rows, so
.shape[0] is 4. Then str(4) is
"4", and "4" * 2 repeats the string twice →
"44".
The average score on this problem was 58%.
courses.get("Enrollment").iloc[0] != courses.get("Enrollment").loc[0]Answer: False
.iloc[0] and .loc[0] both refer to the
first row (label 0), so they read the same enrollment
value. Comparing a value to itself with != is always
False (e.g. 120 != 120).
The average score on this problem was 40%.
courses.shape[1] / 7Answer: 1.0
courses.shape[1] is the number of columns, which is
7 for this DataFrame. So 7 / 7 is
1.0 (division in Python 3 returns a float; 1.
is also acceptable).
The average score on this problem was 78%.
The Registrar wants to calculate what percentage of each course’s
capacity is currently filled. Fill in the blanks to add a new column
called "Percent_Full" to the courses DataFrame
that contains this percentage (as a number between 0 and 100).
courses = courses.assign(Percent_Full = ___(a)___ / ___(b)___ * 100)(a):
Answer: courses.get("Enrollment") —
current enrollment in each row (numerator of the fraction).
The average score on this problem was 86%.
(b):
Answer: courses.get("Capacity")
Percent full is (enrollment ÷ capacity) × 100. Blank (a) is current enrollment per row; blank (b) is max capacity per row. Division is element-wise (row by row), then multiply by 100. For example, 120 enrolled and 150 capacity gives (120/150) × 100 = 80.
The average score on this problem was 86%.