← return to practice.dsc10.com
Below are practice problems tagged for Lecture 8 (rendered directly from the original exam/quiz sources).
Suppose we’ve run the following two lines of code.
first = evs.get("Brand").apply(max)
second = evs.get("Brand").max()Note:
v is defined as
len(v), unless v is a DataFrame, in which case
its length is v.shape[0].s is a string, then max(s) also
evaluates to a string.Fill in the blanks: first is a __(i)__ of length
__(ii)__.
(i):
list
array
string
DataFrame
Series
(ii): _____
Answer:
The .apply method applies a function on every element of
a Series. Here, evs.get("Brand").apply(max) applies the
max function on every element of the "Brand"
column of evs, producing a new Series with the same length
as evs.
While not necessary to answer the question, if s is a
string, then max(s) evaluates to the single character in
s that is last in the alphabet. For instance,
max("zebra") evaluates to "z". As such,
evs.get("Brand").apply(max) is a Series of 32 elements,
each of which is a single character, corresponding to the latest
character in the alphabet for each entry in
evs.get("Brand").
The average score on this problem was 65%.
Fill in the blanks: second is a __(i)__ of length
__(ii)__.
(i):
list
array
string
DataFrame
Series
(ii): _____
Answer:
The .max() method will find the “largest” element in the
Series it is called in, which in this case is
evs.get("Brand"). The way that strings are ordered is
alphabetically, so evs.get("Brand").max() will be the last
value of "Brand" alphabetically. Since we were told that
the only values in the "Brand" column are
"Tesla", "BMW", "Audi", and
"Nissan", the “maximum” is "Tesla", which has
a length of 5.
The average score on this problem was 54%.
Consider the following incomplete assignment statement.
result = evs______.mean()In each part, fill in the blank above so that result evaluates to the specified quantity.
A DataFrame, indexed by "Brand", whose
"Seats" column contains the average number of
"Seats" per "Brand". (The DataFrame may have
other columns in it as well.)
Answer: .groupby("Brand")
When we group by a column, the resulting DataFrame contains one row
for every unique value in that column. The question specified that we
wanted some information per "Brand", which implies
that grouping by "Brand" is necessary.
After grouping, we need to use an aggregation method. Here, we wanted
the resulting DataFrame to be such that the "Seats" column
contained the average number of "Seats" per
"Brand"; this is accomplished by using
.mean(), which is already done for us.
Note: With the provided solution, the resulting DataFrame also has
other columns. For instance, it has a "Range" column that
contains the average "Range" for each "Brand".
That’s fine, since we were told that the resulting DataFrame may have
other columns in it as well. If we wanted to ensure that the only column
in the resulting DataFrame was "Seats", we could have used
.get(["Brand", "Seats"]) before grouping, though this was
not necessary.
The average score on this problem was 76%.
A number, corresponding to the average "TopSpeed" of all
EVs manufactured by Audi in evs
Answer:
[evs.get("Brand") == "Audi"].get("TopSpeed")
There are two parts to this problem:
Querying, to make sure that we only keep the rows corresponding to Audis. This is accomplished by:
evs.get("Brand") == "Audi" to create a Boolean
Series, with Trues for the rows we want to keep and
Falses for the other rows.True. This is accomplished by
evs[evs.get("Brand") == "Audi"] (though the
evs part at the front was already provided).Accessing the "TopSpeed" column. This is
accomplished by using .get("TopSpeed").
Then, evs[evs.get("Brand") == "Audi"].get("TopSpeed") is
a Series contaning the "TopSpeed"s of all Audis, and mean
of this Series is the result we’re looking for. The call to
.mean() was already provided for us.
The average score on this problem was 77%.
A number, corresponding to the average of the natural logarithm of
the "TopSpeed" of all EVs in evs. (Hint: The function
np.log computes the natural logarithm of a single
number.)
Answer:
.get("TopSpeed").apply(np.log)
The .apply method is used to apply a function on every
element of a Series. The relevant Series here is the column containing
the "TopSpeed" of each EV,
i.e. evs.get("TopSpeed") (the evs part was
already provided to us).
After we get that Series, we need to use the function
np.log on every element of it. This is accomplished by
using .apply(np.log). Putting our steps so far together, we
have evs.get("TopSpeed").apply(np.log), which is a Series
containing the natural logarithm of the "TopSpeed" of all
EVs in evs.
The number we were asked for was the average of the natural logarithm
of the "TopSpeed" of all EVs in evs; all we
need to do now is use the .mean() method at the end, which
was already done for us.
The average score on this problem was 61%.
Suppose we want to assign a new column named
"family_size" to living_cost that contains the
total number of people in each family, stored as an int. We do so as
follows.
living_cost = living_cost.assign(
family_size=living_cost.get("family_type").apply(num_people))Which of the following options correctly define the function
num_people such that the line above adds the
"family_size" column as desired? Select all that
apply.
Hint: You can access an individual character in a string
using the position number in square brackets. For example,
"midterm"[0] evaluates to "m" and
"midterm"[1] evaluates to "i".
# Option 1
def num_people(fam):
return int(fam[0]) + int(fam[2])
------------------------------------
# Option 2
def num_people(fam):
return int(fam[0] + fam[2])
------------------------------------
# Option 3
def num_people(fam):
x = int(fam[0] + fam[2])
return int(x / 10) + x % 10
------------------------------------
# Option 4
def num_people(fam):
x = fam.strip("c").split("a")
return int(x[0]) + int(x[1])
------------------------------------
# Option 5
def num_people(fam):
x = 0
for i in fam:
if i % 2 == 0:
x = x + 1
return x
------------------------------------
# Option 6
def num_people(fam):
x = 0
for i in np.arange(len(fam)):
if i % 2 == 0:
x = x + int(fam[i])
return xOption 1
Option 2
Option 3
Option 4
Option 5
Option 6
None of the above.
Answer: Options 1, 3, 4, 6
Option 1: In order to get the number of people within a family, we can look at the character at position 0 (for the number of adults) and the character at position 2 (for the number of children). Converting each character into an int and adding these ints yields the correct results.
Option 2: This is similar to Option 1, however, the key difference is
that the separate strings are concatenated first, then converted into an
integer afterwards. Remember that the plus sign between two strings
concatenates the strings together, and does not add mathematically. For
example, on a family type of "1a2c", "1" and
"2" will be extracted and concatenated together as
"12", then converted to the int 12. This is returned
instead of the value 3 that we are looking for.
Option 3: This option is similar to Option 2, however, it includes an
extra step after concatenation. int(x/10) gets the value in
the tens place, taking advantage of the fact that the int()
function always rounds down. At the same time, x % 10 gets
the value in the ones place by calculating the remainder upon division
by ten. Looking at the example of "1a2c", the first line
will set x = 12 and then int(12/10) will yield
1 while 12 % 10 yields 2. Adding these together achieves
the correct answer of 3.
Option 4: This option is similar to Option 1, but includes the
initial step of removing "c" from the string and separating
by "a". After this, x is a list of two
elements, the first of which represents the number of adults in the
family, and the second of which represents the number of children in the
family. These are separately converted to ints then added up in the last
line.
Option 5: This option iterates through the input string, where
i represents each individual character in the string. For
example, on an input of "1a2c", i is first set
to 1, then a, then 2, then
c. However, calculating the remainder when we divide by two
(i % 2) only makes sense when i is a number,
and results in an error when i is a string.
Option 6: This is a similar approach to Option 5, except this time,
i represents each of the numbers 0, 1, 2, and 3, since
len(fam) is always 4. For each such i, which
we can think of as the position number, the code will check if the
position number is even (i % 2 == 0). This is only true for
position 0 and 2, which are the positions that contain the numbers of
adults and children in the family. When this condition is met, we add
the value at that position onto our running total, x, which
at the end, equals the total number of adults and children in the
family.
The average score on this problem was 73%.
Bill is curious about whether his bookstore is busier on weekends (Saturday, Sunday) or weekdays (Monday, Tuesday, Wednesday, Thursday, Friday). To help figure this out, he wants to define some helpful one-line functions.
The function find_day should take in a given
"date" and return the associated day of the week. For
example, find_day("Saturday, December 7, 2024") should
evaluate to "Saturday".
The function is_weekend should take in a given
"date" and return True if that date is on a
Saturday or Sunday, and False otherwise. For example,
is_weekend("Saturday, December 7, 2024") should evaluate to
True.
Complete the implementation of both functions below.
def find_day(date):
return date.__(a)__
def weekend(date):
return find_day(date)[__(b)__] == __(c)__(a). Answer: split(",")[0]
The function find_day takes in a string that is a date
with the format "Day of week, Month Day, Year", and we want
the "Day of week" part. .split(",") separates
the given string by "," and gives us a list containing the
separated substrings, which looks something like
["Saturday", " December 7", " 2024"]. We want the first
element in the list, so we use [0] to obtain the first
element of the list.
The average score on this problem was 89%.
(b). Answer: 0
This blank follows a call of find_day(date), which
returns a string that is a day of the week, such as
"Saturday". The blank is inside a pair of [],
hinting that we are performing string indexing to pull out a specific
character from the string. We want to determine whether the string is
"Saturday" or "Sunday". The only thing in
common for these two days and is not common for the other five days of
the week is that the string starts with the letter "S".
Thus, we get the first character using [0] in this
blank.
The average score on this problem was 74%.
(c). Answer: "S"
After getting the first character in the string, to check whether it
is the letter "S", we use == to evaluate this
character against "S". This expression will give us a
boolean, either True or False, which is then
returned.
The average score on this problem was 50%.
Now, Bill runs the following line of code:
sales_day = sales.assign(weekend = sales.get("date").apply(is_weekend))Determine which of the following code snippets evaluates to the
proportion of book purchases in sales that were made on a
weekend. Select all that apply.
sales_day[sales_day.get("weekend")].count() / sales_day.shape[0]
sales[sales_day.get("weekend")].shape[0] / sales_day.shape[0]
sales_day.get("weekend").median()
sales_day.get("weekend").mean()
np.count_nonzero(sales_day.get("weekend") > 0.5) / sales_day.shape[0]
Answer:
sales[sales_day.get("weekend")].shape[0] / sales_day.shape[0]sales_day.get("weekend").mean()np.count_nonzero(sales_day.get("weekend") > 0.5) / sales_day.shape[0]First of all, we add a new column called "weekend" to
the sales DataFrame, and this new DataFrame is called
sales_day. The new column contains boolean values that
indicate whether the value in the "date" column is
"Saturday" or "Sunday", which are obtained by
applying is_weekend from the previous question to the
"date" column.
Now, we want to find the proportion of book purchases in sales that
were made on a weekend, which is basically the proportion of rows in the
"weekend" column that are True. Let’s look at
each of the options:
sales_day[sales_day.get("weekend")].count() / sales_day.shape[0]
(incorrect): You can only use .count() on a groupby object.
The correct alternative is to use .shape[0].
sales[sales_day.get("weekend")].shape[0] / sales_day.shape[0]
(correct): sales_day.get("weekend") gets the
"weekend column from the sales_day DataFrame.
We then use this Series to query the sales DataFrame and
keep only the rows corresponding to weekends. Lastly, we count the
number of rows in this filtered DataFrame with .shape[0]
and divide by the total number of sales to get the proportion.
sales_day.get("weekend").median() (incorrect): A
boolean value can be seen as 1 (True) or 0 (False). Since the column
"weekend" contains all booleans, the median falls on either
1 or 0, which is not the proportion that we want.
sales_day.get("weekend").mean() (correct): A boolean
value can be seen as 1 (True) or 0 (False). The mean of the
"weekend" column is equal to the sum of the column divided
the total number of rows in the column. The sum of the column is the sum
of all the 1’s and 0’s, which is just the number of Trues.
The number of Trues divided by the total number of rows is
the proportion of sales on weekend.
np.count_nonzero(sales_day.get("weekend") > 0.5) / sales_day.shape[0]
(correct): A boolean value can be seen as 1 (True) or 0 (False).
sales_day.get("weekend") > 0.5 gives us a Series of
booleans indicating whether the value in "weekend" is
greater than 0.5. If the value is True, then it’s greater
than 0.5. np.count_nonzero counts the number of values that
are not zero, which is the number of Trues. We then divide
the number of Trues by the total number of sales to get the
proportion.
The average score on this problem was 72%.
The "address" column contains quite a bit of
information. All houses are in "San Diego, CA", but the
street address and the zip code vary. Note that the “street address"
includes both the house number and street name, such as
"820 Opal Street". All addresses are formatted in the same
way, for example,
"820 Opal Street, San Diego, CA, 92109".
Fill in the blanks in the function address_part below.
The function has two inputs: a value in the index of treat
and a string part, which is either "street" or
"zip". The function should return the appropriate part of
the address at the given index value, as a string. Example behavior is
given below.
>>> address_part(4, "street")
"8575 Jade Coast Drive"
>>> address_part(1, "zip")
"92109"The function already has a return statement included. You should not
add the word return anywhere else!
def address_part(index_value, part):
if part == "street":
var = 0
else:
___(a)___
return treat.get("address").loc[___(b)___].___(c)___Answer:
(a): var = 3, var = -1 or alternate
solution var = 1
(b): index_value
(c): split(", ")[var] or alternate solution
split(", San Diego, CA, ")[var]
The average score on this problem was 58%.
Suppose we had a different function called zip_as_int
that took as input a single address, formatted exactly as the addresses
in treat, and returned the zip code as an int.
Write a Python expression using the zip_as_int function
that evaluates to a Series with the zip codes of all the addresses in
treat.
Answer:
treat.get("address").apply(zip_as_int)
The average score on this problem was 76%.
Typically, graduation ceremonies happen only at the end of an academic year. For example, students who earn a degree in the 2024-2025 academic year celebrate with a graduation ceremony in 2025.
The function ceremony_year takes as input a string
formatted like those in the "Year" column of , and
returns an int corresponding to the year of the
graduation ceremony for that academic year. For example,
ceremony_year("2024-2025") should return 2025.
Fill in the return statement of this function below.
def ceremony_year(academic_year):
returnAnswer:
int(academic_year.split("-")[1])
The average score on this problem was 70%.
What does the following expression evaluate to? Write your answer exactly how the output would appear in Python.
uc.get("Year").apply(ceremony_year).min()Answer: 2019
The average score on this problem was 87%.
Each value in the "ps" column is a string formatted like
"(word, tag)", where the first part is the word and the
second part is a tag indicating the word’s part of speech
(e.g. "(getting, VBG)"). Note that the word and the part of
speech tag are each enclosed in single quotes. To clean the column so
that "ps" contains only the part of speech
tag, we run the following line of code.
words = words.assign(ps = words.get("ps").apply(fix_ps))After we run this line of code, the first five rows of
words should appear as follows.
Which of the following options correctly define the function
fix_ps to produce the desired result? Select all
that apply.
def fix_ps(x): return x.split("'")[3]
def fix_ps(x): return x.split(",")[1].strip("')")
def fix_ps(x): return x.split(", ")[1].strip("')")
def fix_ps(x): return x.split(", ")[1].strip(")").strip("'")
def fix_ps(x): return x.split(", ")[1].strip("'").strip(")")
None of the above.
Let’s consider all the answer options using
x = "(’getting’, ’VBG’)" as our example.
Option 1:
x.split("’") = ["(", "getting", ", ", "VBG", ")"][3] = "VBG"
This is exactly what we want.
Option 2:
1. x.split(",") = ["(’getting’", " ’VBG’)"][1] = " ’VBG’)"
2. " ’VBG’)" .strip("’)") = " ’VBG"
Note that strip does not remove the exact substring it’s
given; instead, it removes all leading and trailing characters that
appear in the given set of characters.So, this code removes any
leading/trailing instances of single quote "’" and right
parenthesis ")". " ’VBG’)" starts with a
space, which is not in the argument to strip, so nothing is
removed from the front. It ends with both "’" and
")", so both are removed, leaving " ’VBG".
Thus, this option is incorrect.
Option 3:
1. x.split(", ") = ["(’getting’", "’VBG’)"][1] = "’VBG’)"
2. "’VBG’)" .strip("’)") = "VBG"
Here, strip removes any leading and trailing instances of
"’" and ")". "’VBG’)" starts with
"’", which is removed; it ends with "’" and
")", which are also removed, leaving "VBG".
Thus, this option is correct.
Option 4:
1. x.split(", ") = ["(’getting’", "’VBG’)"][1] = "’VBG’)"
2. "’VBG’)" .strip(")") = "’VBG’"
3. "’VBG’" .strip("’") = "VBG"
The first strip removes any leading and trailing instances of
")", so the last character of "’VBG’)" is
removed to become "’VBG’". The second strip removes any
leading and trailing instances of "’", so the first and
last characters of "’VBG’" are removed to become
"VBG". Thus, this option is correct.
Option 5:
1. x.split(", ") = ["(’getting’", "’VBG’)"][1] = "’VBG’)"
2. "’VBG’)".strip(" ’") = "VBG’)"
3. "VBG’)".strip(")") = "VBG’"
The first strip removes any leading and trailing instances of
" " and "’", so the first character of
"’VBG’)" is removed to become "VBG’)". The
second strip removes any leading and trailing instances of
")", so the last character of "VBG’)" is
removed to become "VBG’". Incorrect.
Therefore, the correct options are 1, 3, and 4.
The average score on this problem was 57%.
For a typical diet, the recommended daily protein intake is 80 g.
Fill in the blanks in the code below to add a new column to
chipotle that contains values 0 to 100 representing the
percentage of the recommended daily protein intake each ingredient
provides.
def clean_protein(grams):
return int(grams.split(" ")[__(a)__]) / __(b)__ * 100
chipotle = chipotle.assign(protein_percent = __(c)__) (a): 0
(b): 80
(c):
chipotle.get("protein").apply(clean_protein)
The average score on this problem was 88%.
In the ikea DataFrame, the first word of each string in
the 'product' column represents the product line. For
example the HEMNES line of products includes several different products,
such as beds, dressers, and bedside tables.
The code below assigns a new column to the ikea
DataFrame containing the product line associated with each product.
(ikea.assign(product_line = ikea.get('product')
.apply(extract_product_line)))What are the input and output types of the
extract_product_line function?
takes a string as input, returns a string
takes a string as input, returns a Series
takes a Series as input, returns a string
takes a Series as input, returns a Series
Answer: takes a string as input, returns a string
To use the Series method .apply, we first need a Series,
containing values of any type. We pass in the name of a function to
.apply and essentially, .apply calls the given
function on each value of the Series, producing a Series with the
resulting outputs of those function calls. In this case,
.apply(extract_product_line) is called on the Series
ikea.get('product'), which contains string values. This
means the function extract_product_line must take strings
as inputs. We’re told that the code assigns a new column to the
ikea DataFrame containing the product line associated with
each product, and we know that the product line is a string, as it’s the
first word of the product name. This means the function
extract_product_line must output a string.
The average score on this problem was 72%.
Complete the return statement in the
extract_product_line function below.
def extract_product_line(x):
return _________What goes in the blank?
Answer: x.split(' ')[0]
This function should take as input a string x,
representing a product name, and return the first word of that string,
representing the product line. Since words are separated by spaces, we
want to split the string on the space character ' '.
It’s also correct to answer x.split()[0] without
specifying to split on spaces, because the default behavior of the
string .split method is to split on any whitespace, which
includes any number of spaces, tabs, newlines, etc. Since we’re only
extracting the first word, which will be separated from the rest of the
product name by a single space, it’s equivalent to split using single
spaces and using the default of any whitespace.
The average score on this problem was 84%.
Recall that an IKEA fan created an app for people to log the amount
of time it takes them to assemble an IKEA product. We have this data in
app_data.
Suppose that when someone downloads the app, the app requires them to choose a username, which must be different from all other registered usernames.
True or False: If app_data had included
a column with the username of the person who reported each product
build, it would make sense to index app_data by
username.
True
False
Answer: False
Even though people must have distinct usernames, one person can build
multiple different IKEA products and log their time for each build. So
we don’t expect every row of app_data to have a distinct
username associated with it, and therefore username would not be
suitable as an index, since the index should have distinct values.
The average score on this problem was 52%.
What does the code below evaluate to?
(app_data.take(np.arange(4))
.sort_values(by='assembly_time')
.get('assembly_time')
.iloc[0])Hint: The 'assembly_time' column contains
strings.
Answer: '1 hr, 45 min'
The code says that we should take the first four rows of
app_data (which we can see in the preview at the start of
this exam), sort the rows in ascending order of
'assembly_time', and extract the very first entry of the
'assembly_time' column. In other words, we have to find the
'assembly_time' value that would be first when sorted in
ascending order. As given in the hint, the 'assembly_time'
column contains strings, and strings get sorted alphabetically, so we
are looking for the assembly time, among the first four, that would come
first alphabetically. This is '1 hr, 45 min'.
Note that first alphabetically does not correspond to the least
amount of time. '1 hr, 5 min' represents less time than
'1 hr, 45 min', but in alphabetical order
'1 hr, 45 min' comes before '1 hr, 5 min'
because both start with the same characters '1 hr, ' and
comparing the next character, '4' comes before
'5'.
The average score on this problem was 46%.
Complete the implementation of the to_minutes function
below. This function takes as input a string formatted as
'x hr, y min' where x and y
represent integers, and returns the corresponding number of minutes,
as an integer (type int in Python).
For example, to_minutes('3 hr, 5 min') should return
185.
def to_minutes(time):
first_split = time.split(' hr, ')
second_split = first_split[1].split(' min')
return _________What goes in the blank?
Answer:
int(first_split[0])*60+int(second_split[0])
As the last subpart demonstrated, if we want to compare times, it
doesn’t make sense to do so when times are represented as strings. In
the to_minutes function, we convert a time string into an
integer number of minutes.
The first step is to understand the logic. Every hour contains 60
minutes, so for a time string formatted like x hr, y min'
the total number of minutes comes from multiplying the value of
x by 60 and adding y.
The second step is to understand how to extract the x
and y values from the time string using the string methods
.split. The string method .split takes as
input some separator string and breaks the string into pieces at each
instance of the separator string. It then returns a list of all those
pieces. The first line of code, therefore, creates a list called
first_split containing two elements. The first element,
accessed by first_split[0] contains the part of the time
string that comes before ' hr, '. That is,
first_split[0] evaluates to the string x.
Similarly, first_split[1] contains the part of the time
string that comes after ' hr, '. So it is formatted like
'y min'. If we split this string again using the separator
of ' min', the result will be a list whose first element is
the string 'y'. This list is saved as
second_split so second_split[0] evaluates to
the string y.
Now we have the pieces we need to compute the number of minutes,
using the idea of multiplying the value of x by 60 and
adding y. We have to be careful with data types here, as
the bolded instructions warn us that the function must return an
integer. Right now, first_split[0] evaluates to the string
x and second_split[0] evaluates to the string
y. We need to convert these strings to integers before we
can multiply and add. Once we convert using the int
function, then we can multiply the number of hours by 60 and add the
number of minutes. Therefore, the solution is
int(first_split[0])*60+int(second_split[0]).
Note that failure to convert strings to integers using the
int function would lead to very different behavior. Let’s
take the example time string of '3 hr, 5 min' as input to
our function. With the return statement as
int(first_split[0])*60+int(second_split[0]), the function
would return 185 on this input, as desired. With the return statement as
first_split[0]*60+second_split[0], the function would
return a string of length 61, looking something like this
'3333...33335'. That’s because the * and
+ symbols do have meaning for strings, they’re just
different meanings than when used with integers.
The average score on this problem was 71%.
You want to add to app_data a column called
'minutes' with integer values representing the number of
minutes it took to assemble each product.
app_data = app_data.assign(minutes = _________)
app_dataWhich of the following should go in the blank?
to_minutes('assembly_time')
to_minutes(app_data.get('assembly_time'))
app_data.get('assembly_time').apply(to_minutes)
app_data.get('assembly_time').apply(to_minutes(time))
Answer:
app_data.get('assembly_time').apply(to_minutes)
We want to create a Series of times in minutes, since it’s to be
added to the app_data DataFrame using .assign.
The correct way to do that is to use .apply so that our
function, which works for one input time string, can be applied
separately to every time string in the 'assembly_time'
column of app_data. Remember that .apply takes
as input one parameter, the name of the function to apply, with no
arguments. The correct syntax is
app_data.get('assembly_time').apply(to_minutes).
The average score on this problem was 98%.
Fill in the blanks below so that the expression evaluates to the most unread emails of any student that has 0 Instagram followers.
survey[__(a)__].__(b)__What goes in blank (a)?
Answer:
survey.get("IG Followers") == 0
survey.get("IG Followers") is a Series containing the
values in the "IG Followers" column.
survey.get("IG Followers") == 0, then, is a Series of
Trues and Falses, containing True
for rows where the number of "IG Followers" is 0 and
False for all other rows.
Put together, survey[survey.get("IG Followers") == 0]
evaluates to a new DataFrame, which only has the rows in
survey where the student’s number of
"IG Followers" is 0.
The average score on this problem was 89%.
What goes in blank (b)? Select all valid answers.
get("Unread Emails").apply(max)
get("Unread Emails").max()
sort_values("Unread Emails", ascending=False).get("Unread Emails").iloc[0]
sort_values("Unread Emails", ascending=False).get("Unread Emails").iloc[-1]
None of the above
Answer: Options 2 and 3
Let’s look at each option.
get("Unread Emails").apply(max) This option is invalid
because .apply(max) will produce a new Series containing
the maximums of each individual element in "Unread Emails"
rather than the maximum of the entire column. Since the values in the
"Unread Emails" columns are numbers, this will try to call
max on a number individually (many times), and that errors,
since e.g. max(2) is invalid.get("Unread Emails").max()
This option is valid because it directly fetches the
"Unread Emails" column and uses the max method
to retrieve the highest value within it, aligning with the goal of
identifying the most unread emails.sort_values("Unread Emails", ascending=False).get("Unread Emails").iloc[0]
This option is valid. The
sort_values("Unread Emails", ascending=False) method call
sorts the "Unread Emails" column in descending order.
Following this, .get("Unread Emails") retrieves the sorted
column, and .iloc[0] selects the first element, which,
given the sorting, represents the maximum number of unread emails.sort_values("Unread Emails", ascending=False).get("Unread Emails").iloc[-1]
This option is invalid because, although it sorts the
"Unread Emails" column in descending order, it selects the
last element with .iloc[-1], which represents the smallest
number of unread emails due to the descending sort order.
The average score on this problem was 89%.
Now, consider the following block of code.
temp = survey.groupby(["IG Followers", "College"]).max().reset_index()
revellian = temp[__(c)__].get("Unread Emails").__(d)__Fill in the blanks below so that revellian is equal to
the most unread emails of any student in Revelle, among those with 0
Instagram followers.
What goes in blank (c)?
Answers:
(temp.get("College") == "Revelle") & (temp.get("IG Followers") == 0)
To identify the students in "Revelle" with
0 Instagram followers, we filter the temp
DataFrame using two conditions: (temp["IG Followers"] == 0)
ensures students have no Instagram followers, and
(temp["College"] == "Revelle") ensures the student is from
"Revelle". The & operator combines these
conditions, resulting in a subset of students from
"Revelle" with 0 Instagram followers.
The average score on this problem was 54%.
What goes in blank (d)?
Answer: iloc[0], iloc[-1],
sum(), max(), mean(), or any
other method that when called on a Series with a single value outputs
that same value
To create temp, we grouped on both
"IG Followers" and "College" and used the
max aggregation method. This means that temp
has exactly one row where "College" is
"Revelle" and "IG Followers" is 0, since when
we group on both "IG Followers" and "College",
the resulting DataFrame has exactly one row for every unique combination
of "IG Followers" and "College" name. We’ve
already identified that before blank (d) is
temp[(temp.get("College") == "Revelle") & (temp.get("IG Followers") == 0)].get("Unread Emails")Since
temp[(temp.get("College") == "Revelle") & (temp.get("IG Followers") == 0)]
is a DataFrame with just a single row, the entire expression is a Series
with just a single value, being the maximum value we ever saw in the
"Unread Emails" column when "College" was
"Revelle" and "IG Followers" was 0. To extract
the one element out of a Series that only has one element, we can use
many aggregation methods (max, min,
mean, median) or use .iloc[0] or
.iloc[-1].
The average score on this problem was 79%.
The student in Revelle with the most unread emails, among those with
0 Instagram followers, is a "HI25" (History) major. Is the
value "HI25" guaranteed to appear at least once within
temp.get("Major")?
Yes
No
Answer: No
When the survey DataFrame is grouped by both
"IG Followers" and "College" using the
.max aggregation method, it retrieves the maximum value for
each column based on alphabetical order. Even if a student in
"Revelle" with 0 Instagram followers has the most unread
emails and is a "HI25" major, the "HI25" value
would only be the maximum for the "Major" column if no
other major code in the same group alphabetically surpasses it.
Therefore, if there’s another major code like "HI26" or
"MA30" in that group, it would be chosen as the maximum
instead of "HI25".
The average score on this problem was 59%.
Values in the "Bath" column are "One",
"One and a half", "Two",
"Two and a half", and "Three". Fill in the
blank in the function float_bath that will convert any
string from the "Bath" column into its corresponding number
of bathrooms, as a float. For example,
float_bath("One and a half") should return
1.5.
def float_bath(s):
if "One" in s:
n_baths = 1
elif "Two" in s:
n_baths = 2
else:
n_baths = 3
if "and a half" in s:
__(a)__
return n_bathsWhat goes in blank (a)?
Answer: n_baths = n_baths + 0.5
The behavior that we want this line of code to have is to work
regardless if the bath string contains "One",
"Two", or "Three". This means we need to have
some way of taking the value that n_baths is already
assigned and adding 0.5 to it. So, our code should read
n_baths = n_baths + 0.5.
The average score on this problem was 92%.
Values in the "Lease Term" column are
"1 month", "6 months", and
"1 year". Fill in the blanks in the function
int_lease() that will convert any string from the
"Lease Term" column to the corresponding length of the
lease, in months, as an integer.
def int_lease(s):
if s[-1] == "r":
return __(b)__
else:
return __(c)__What goes in blanks (b) and (c)?
Answer:
(b): 12(c): int(s[0])The code in blank (b) will only be run if the last letter of
s is "r", which only happens when
s = "1 year". So, blank (b) should return
12.
The code in blank (c) will run when s has any value
other than "1 year". This includes only two options:
1 month, and 6 months. In order to get the
corresponding number of the months for these two string values, we just
need to take the first character of the string and convert it from a
str type to an int type. So, blank (c) should
return int(s[0]).
The average score on this problem was 84%.
The average score on this problem was 67%.
Values in the "Bed" column are "Studio",
"One", "Two", and "Three". The
function int_bed provided below converts any string from
the "Bed" column to the corresponding number of bedrooms,
as an integer. Note that "Studio" apartments count as
having 0 bedrooms.
def int_bed(s):
if s == "Studio":
return 0
elif s == "One":
return 1
elif s == "Two":
return 2
return 3Using the provided int_bed function, write one line of
code that modifies the "Bed" column of the
apts DataFrame so that it contains integers instead of
strings.
Important: We will assume throughout the rest of
this exam that we have converted the "Bed" column of
apts so that it now contains ints.
Answer:
apts = apts.assign(Bed = apts.get("Bed").apply(int_bed))
The code above takes the “Bed” column, apts.get("Bed"),
and uses .apply(int_bed), which runs each entry through the
int_bed function that we have defined above. All that is
left is to save the result back to the dataframe; this can be done with
.assign().
The average score on this problem was 68%.
Fill in the blanks in the function sum_phone below. This
function should take as input a string representing a phone number,
given in the form "xxx-xxx-xxxx", and return the sum of the
digits of that phone number, as an int.
For example, sum_phone("501-800-3002") should evaluate
to 19.
def sum_phone(phone_number):
total = 0
for digit in phone_number:
if ___(a)___:
___(b)___
return totalAnswer:
digit != "-"total = total + int(digit)digit is a number, and the
only character in the string of the phone_number is the
hyphen (-). For instance, in the given phone number of
"501-800-3002", we want to extract the actual numbers in
the string, without the hyphens. So, because we cannot establish a
numerical value to a hyphen, we exclude it.
The average score on this problem was 34%.
The average score on this problem was 71%.
Recall from the data description that the "DOB" column
in contacts contains the date of birth of everyone in your
contacts list, as a string formatted like "MM-DD-YYYY".
Looking at the calendar, you see that today’s date is May 3rd, 2024,
which is "05-03-2024".
Using today’s date, fill in the blanks in the function
age_today so that the function takes as input someone’s
date of birth, as a string formatted like "MM-DD-YYYY", and
returns that person’s age, as of today.
def age_today(dob):
dob = dob.split("-")
month = ___(a)___ # the month, as an int
day = ___(b)___ # the day, as an int
year = ___(c)___ # the year, as an int
if ___(d)___:
return 2024 - year
return 2024 - year - 1Answer:
int(dob[0])int(dob[1])int(dob[2])(month < 5) or (month == 5 and day <= 3).split() method divides a string into a list based on delimiter. In
this probelm, dob.split("-") returns a list of substrings
that were separated by hyphens in the original string formatted like
"MM-DD-YYYY". Thus, after using the .split("-"), the resulting list will be formatted like[“MM”,
“DD”, “YYYY”]. Thus, we can access month, day, year by its position in
the list dob.
Note that the comment asks month, day, year as int, do we need to
convert them from string to int datatype, by using int(). Thus, we have
month = int(dob[0]), day = int(dob[1]),
year = int(dob[2]). This is for us to calculate age later
by comparing month and day numebrs.
Then to calculate the age of the person given today is “05-03-2024”,
we can use 2024-year. But if a person is born after May
3rd, then they are techinically 1 year younger than that, so we should
use 2024-year-1. Thus in the if statment, we use
(month < 5) or (month == 5 and day <= 3) to compare
if the person is born in January, February, March, April or one of the
first three days of May.
The average score on this problem was 59%.
Write a Python expression that evaluates to the average age of all of your contacts, as of today.
Answer:
contacts.get("DOB").apply(age_today).mean()
contacts.get("DOB") gets the column ‘DOB’ column in
contacts DataFrame as a series.
.apply(age_today) applies the function
age_today to each element in the series to calculate age,
and returns a series of ages of all contacts.
.mean() calculates the average of the series, giving the
average age of all contacts.
The average score on this problem was 80%.
In tariffs, we use integers to represent percentages,
but we could also use strings with the percent symbol %. For example,
the integer 34 and the string "34%" both
represent the same thing.
Fill in the functions with_percent_symbol and
without_percent_symbol below. The function
with_percent_symbol should take as input an integer and
give as output a string with the percent symbol. The function
without_percent_symbol should do the opposite. Example
behavior is given below.
>>> with_percent_symbol(34)
"34%"
>>> without_percent_symbol("34%")
34
def with_percent_symbol(x):
return __(a)__
def without_percent_symbol(x):
return __(b)__Answer (a): str(x)+"%"
In order to add a percent symbol to the end, we first need to convert
the variable x from an integer into a string by casting it.
From there we can add a "%" sign to x through
concatenation.
The average score on this problem was 70%.
Answer (b): int(x.replace("%", "")) or
int(x.strip("%"))
In this case, the variable x is now a string with
"%" at the end of it. Our first step is to get rid of the
"%" at the end by either replacing it with an empty string
"", or stripping it from the end. Note that the
.strip("%") approach works because "%" is at
the end of the string. If it were in the middle instead of the start or
end, .strip("%") would not work. After we are left with
only the number to cast to a string value for our output.
The average score on this problem was 79%.
Define the variable y as follows.
y = tariffs.get("Reciprocal Tariff").apply(with_percent_symbol)Below, define z so that it evaluates to exactly the same
Series as y. You may not use
with_percent_symbol or y when defining
z.
Answer:
z = tariffs.get("Reciprocal Tariff").apply(str) + "%"
The Reciprocal Tariff column consists of integer values.
In order to add a percent sign (“%”) to the end of each of these values,
we must first convert the Series of integers into a Series of strings
before we are able to concatenate each with the percent sign (“%”).
The average score on this problem was 33%.
Determine the value of the following expression.
y.iloc[3] + " tax on goods from " + tariffs.get("Country").loc[3]Answer:
"32% tax on goods from Taiwan"
y.iloc[3] consists of the Reciprocal Tariff (as a
string) corresponding to the fourth entry of the Series y. From the
given DataFrame, the fourth row corresponds to a Reciprocal Tariff 32.
Because y is a Series of strings that added the “%” sign to each
Reciprocal Tariff, y.iloc[3] evaluates to the string “32%”.
tariffs.get("Country").loc[3] evaluates to the country at
the fourth position from the tariffs DataFrame, or
“Taiwan”.
The average score on this problem was 88%.
Fill in the blanks below to add a new column to ghibli
called "TimeString", containing the runtime of each film as
a string in hours and minutes. For example, Spirited Away is
125 minutes long, so its value in the "TimeString" column
would be "2 hours, 5 minutes".
def change_time(mins):
hours = ___(a)___
minutes = ___(b)___
return str(hours) + " hours, " + str(minutes) + " minutes"
ghibli = ghibli.assign(TimeString = ___(c)___)Answer (a): int(mins / 60)
The average score on this problem was 73%.
Answer (b): mins % 60
The average score on this problem was 62%.
Answer (c):
ghibli.get("Runtime").apply(change_time)
The average score on this problem was 85%.
Which column of kart would work best as the index?
"Ranking"
"Team"
"Division"
"Total Points"
Answer: "Team"
Recall a choice for a good index would be a column wherein the values
would act as a unique identifier for a particular observation. The only
column that suits this description would be “Team” since
each row represents a unique team.
The average score on this problem was 86%.
Write a line of python code that sets the index of kart
to the column that you identified in part (1).
Answer:
kart = kart.set_index("Team")
We use set_index(“Team”) to set the DataFrame’s index to
“Team” and set this equal to kart to save this
change.
The average score on this problem was 81%.
Fill in the blanks below to complete the implementation of the
function division_to _int, which takes in a string,
division, the name of a division, and returns the
division’s number as an int. Example behavior is given
below.
>>> division_to_int("Division 1")
1
>>> division_to_int("Division 2")
2def division_to_int(division):
__(i)__ __(ii)__(division.__(iii)__[__(iv)__])Answer:
returnintsplit() or
split(" ")-1 or 1Using the argument division, we just want to retrieve
the number. To accomplish this, we can use split() on the
division to separate the string in order to access the
number. Note that the default behavior of split() is to
split by the space.
The output of division.split() is now a list of
“Division” and the number. To retrieve the number in this
list, we can index for it with either -1 (since it is the last element
of the list) or 1 (since it is the second element in the list). Because
we want the output to be an integer type, we use int to
cast the value to an integer. Finally, to have the function output the
desired value, we start with a return statement.
The average score on this problem was 67%.
The average score on this problem was 71%.
The average score on this problem was 52%.
The average score on this problem was 52%.
Write a single line of code that applies
division_to_int to the existing "Division"
column, and updates the "Division" column in
kart.
Answer:
kart.assign(Division=kart.get("Division").apply(division_to_int))
First let’s start by getting the information we want for the new
column. We get the column for transformation with
kart.get(“Division”) and use
.apply(division_to_int) in order to apply the function to
this column. In order to update this transformed Series as a column
“Division”, we use the .assign method on the
DataFrame and set the transformed Series to the column name
“Division”. Note that when using .assign to
add a column and the chosen column name already exists,
.assign will update the information in this column with the
new input information.
The average score on this problem was 81%.
For the rest of this exam, assume that the changes above have not
been made and that kart is the same DataFrame that was
described on the attached information sheet.
Which of the following best describes the input and output types of
the .apply Series method?
input: string, output: Series
input: Series, output: function
input: function, output: Series
input: function, output: function
Answer: input: function, output: Series
It helps to think of an example of how we typically use
.apply. Consider a DataFrame called books and
a function called year_to_century that converts a year to
the century it belongs to. We might use .apply as
follows:
books.assign(publication_century = books.get('publication_year').apply(year_to_century))
.apply is called a Series method because we use it on a
Series. In this case that Series is
books.get('publication_year'). .apply takes
one input, which is the name of the function we wish to apply to each
element of the Series. In the example above, that function is
year_to_century. The result is a Series containing the
centuries for each book in the books DataFrame, which we
can then assign back as a new column to the DataFrame. So
.apply therefore takes as input a function and outputs a
Series.
The average score on this problem was 98%.
Note that each part of Question 3 depends on previous parts of Question 3.
In this question, we’ll take a closer look at the
'material' column of sky.
Below, fill in the blank to complete the implementation of the
function majority_concrete, which takes in the name of a
city and returns True if the majority of the
skyscrapers in that city are made of concrete, and False
otherwise. We define “majority” to mean “at least
50%”.
def majority_concrete(city):
all_city = sky[sky.get('city') == city]
concrete_city = all_city[all_city('material') == 'concrete']
proportion = ______
return proportion >= 0.5What goes in the blank?
Answer:
concrete_city.shape[0] / all_city.shape[0]
Let’s first understand the code that is already provided for us. Note
that city is a string corresponding to the name of a
city.
all_city contains only the rows for the passed in
city. Note that all_city.shape[0] or
len(all_city) is the number of rows in
all_city, i.e. it is the number of skyscrapers in
city. Then, concrete_city contains only the
rows in all_city corresponding to 'concrete'
skyscrapers, i.e. it contains only the rows corresponding to
'concrete' skyscrapers in city. Note that
concrete_city.shape[0] or len(concrete_city)
is the number of skyscrapers in city that are made of
'concrete'.
We want to return True only if at least 50% of the
skyscrapers in city are made of concrete. The last line in
the function, return proportion >= 0.5, is already
provided for us, so all we need to do is compute the proportion of
skyscrapers in city that are made of concrete. This is
concrete_city.shape[0] / all_city.shape[0].
Another possible answer is
len(concrete_city) / len(all_city).
The average score on this problem was 85%.
Below, we create a DataFrame named by_city.
by_city = sky.groupby('city').count().reset_index()Below, fill in the blanks to add a column to by_city,
called 'is_majority', that contains the value
True for each city where the majority of skyscrapers are
concrete, and False for all other cities. You may need to
use the function you defined in the previous subpart.
by_city = by_city.assign(is_majority = ______)What goes in the blank?
Answer:
by_city.get('city').apply(majority_concrete)
We are told to add a column to by_city. Recall, the way
that .assign works is that the name of the new column comes
before the = symbol, and a Series (or array) containing the
values for the new column comes after the = symbol. As
such, a Series needs to go in the blank.
majority_concrete takes in the name of a single
city and returns either True or
False accordingly. All we need to do here then is use the
majority_concrete function on every element in the
'city' column. After accessing the 'city'
column using by_city.get('city'), we need to use the
.apply method using the argument
majority_concrete. Putting it all together yields
by_city.get('city').apply(majority_concrete), which is a
Series.
Note: Here, by_city.get('city') only works because
.reset_index() was used in the line where
by_city was defined. If we did not reset the index,
'city' would not be a column!
The average score on this problem was 86%.
by_city now has a column named
'is_majority' as described in the previous subpart. Now,
suppose we create another DataFrame, mystery, below:
mystery = by_city.groupby('is_majority').count()What is the largest possible value that mystery.shape[0]
could evaluate to?
Answer: 2
Recall, the 'is_majority' column we created in the
previous subpart contains only two possible values – True
and False. When we group by_city by
'is_majority', we create two “groups” – one for
True and one for False. As such, no matter
what aggregation method we use (here we happened to use
.count()), the resulting DataFrame will only have 2 rows
(again, one for True and one for False).
Note: The question asked for the “largest possible value” that
mystery.shape[0], because it is possible that
mystery only has 1 row. This can only happen in two
cases:
'concrete'.'concrete'.
The average score on this problem was 76%.
Suppose
mystery.get('city').iloc[0] == mystery.get('city').iloc[1]
evaluates to True.
True or False: In exactly half of the cities in
sky, it is true that a majority of skyscrapers are made of
'concrete'. (Tip: Walk through
the manipulations performed in the previous three subparts to get an
idea of what mystery looks like and contains.)
True
False
Answer: True
In the solution to the previous subpart, we noted that
mystery contains at most 2 rows, one corresponding to
cities where 'is_majority' is True and one
corresponding to cities where 'is_majority' is
False. Furthermore, recall that we used the
.count() aggregation method, which means that the entries
in each column of mystery contain the
number of cities where 'is_majority' is
True and the number of cities where
'is_majority' is False.
If
mystery.get('city').iloc[0] == mystery.get('city').iloc[1],
it must be the case that the number of cities where
'is_majority' is True and False
are equal. This must mean that in exactly half of the cities in
sky, it is true that the majority of skyscrapers are made
of 'concrete'.
The average score on this problem was 69%.
Let’s start by correcting the data in the "Rating"
column. All the values in this column are strings of length 4. In
addition, some strings use commas in place of a dot to represent a
decimal point. Select the options below that evaluate to a Series
containing the values in the "Rating" column, appropriately
changed to floats.
Note: The Series method .str.replace
uses the string method .replace on every string in a
Series.
float(games.get("Rating").str.replace(",", "."))
games.get("Rating").str.replace(",", ".").apply(float)
games.get("Rating").str.replace(",", "").apply(int)/100
games.get("Rating").str.replace(",", "").apply(float)
Important! For the rest of this exam, we will assume
that the values in the "Rating" column have been correctly
changed to floats.
Answer: Option 2
Option 1: Let’s look at the code piece by piece to
understand why this does not work. games.get("Rating")
gives you the column "Rating" as a Series. As per the note,
.str.replace(",", ".") can be used on a Series, and will
replace all commas with periods. The issue is with the use of the
float function; the float function can convert
a single string to a float, like float("3.14"), but not an
entire Series of floats. This will cause an error making this option
wrong.
Option 2: Once again we are getting
"Rating" as a Series and replacing the commas with periods.
We then apply float() to the Series, which will
successfully convert all of the values into floats.
Option 3: This piece of code attempts to replace
commas with nothing, which is correct for values using commas as decimal
separators. However, this approach ignores values that use dots as
decimal separators. Something like
games.get("Rating").str.replace(",", "").str.replace(".", "").apply(int)/100
could correct this mistake.
Option 4: Again, we are getting
"Rating" as a Series and replacing the commas with an empty
string. The values inside of "Rating" are then converted to
floats, which is fine, but remember, that the numbers are 100 times too
big. This means we have altered the actual value inappropriately, which
makes this option incorrect.
The average score on this problem was 67%.
The "Date" column stores the year, month, and day
together in a single 8-digit int. The first four digits
represent the year, the next two represent the month, and the last two
represent the day. For example, 19500812 corresponds to
August 12, 1950. The get month function below takes one
such 8-digit int, and only returns the
month as an int. For example,
get month(19500812) evaluates to 8.
def get_month(date):
return int((date % 10000) / 100)Similarily, the get year and get day
functions below should each take as input an 8-digit int
representing a date, and return an int representing the
year and day, respectively. Choose the correct code to fill in the
blanks.
def get_year(date):
return ____(a)____def get_day(date):
return ____(b)____What goes in blank (a)?
date / 10000
int(date / 10000)
int(date % 10000)
int((date % 10000) / 10000)
Answer: int(date/10000)
The problem is asking us to find the code for blank (a) and
get_year is asking us to find the year. Let’s use
19500812 as an example, so we need to convert
19500812 to 1950. If we plug in Option 2
for (a) we will get 1950. This is because \frac{19500812}{10000} = 1950.0812, and when
int() is applied to 1950.0812 then it will drop the
decimal, which returns 1950.
Option A: date / 10000 If we plugged in
Option 1 into blank (a) we would get: \frac{19500812}{10000} = 1950.0812. This is a
float and is not equal to 1950.
Option C: int(date % 10000) If we
plugged in Option 3 into blank (a) we would get: 812. Remember,
% is the operation to find the remainder. We can manually
find the remainder by doing \frac{19500812}{10000} = 1950.0812, then
looking at the decimal, and noticing 812 cannot be divided by 10000
evenly. This is an int, but not the year.
Option D: int((date % 10000) / 10000)
If we plugged in Option 4 into blank (a) we would get: 0.0812. We get
this number by once again looking at the remainder of \frac{19500812}{10000} = 1950.0812, which is
812, and then dividing 812 by 10000. This is a float and is not equal to
1950.
The average score on this problem was 67%.
What goes in blank (b)?
int(date / 100)
int(date / 1000000)
int((date % 100) / 10000)
date % 100
Answer: date % 100
The problem is asking us to find the code for blank (b) and
get_day is asking us to get the day. Let’s use
19500812 as the example again, so we need to convert
19500812 to 12. Remember, % is the operation
to find the remainder. If we plug in Option 4 for (b)
we will get 12. This is because \frac{19500812}{100} = 195008.12 and by
looking at the decimal place we notice 12 cannot be divided by 100
evenly, making the remainder 12.
Option 1: int(date / 100) If we plugged
in Option 1 into blank (b) we would get 195008. This is because Python
would do: \frac{19500812}{100} =
195008.12 then would drop the decimal due to the
int() function. This is not the day.
Option 2: int(date / 1000000) If we
plugged in Option 2 into blank (b) we would get 19. This is because
Python would do: \frac{19500812}{1000000} =
19.500812 then would drop the decimal due to the
int() function. This is a day, but not the one we
are looking for.
Option 3: int((date % 100) / 10000) If
we plugged in Option 3 into blank (b) we would get 0. This is because
Python works from the inside out, so it will first evaluate the
remainder: \frac{19500812}{100} =
195008.12, by looking at the decimal place we notice 12 cannot be
divided by 100 evenly, making the remainder 12. Python then does \frac{12}{10000} = 0.0012. Remember that
int() drops the decimal, so by plugging a date into this
code it will return 0, which is not a day.
The average score on this problem was 56%.
Important! For the rest of the exam, assume those
three functions have been implemented correctly and the following code
has been run to assign three new columns to storms.
storms = storms.assign(Year = storms.get("Date").apply(get_year),
Month = storms.get("Date").apply(get_month),
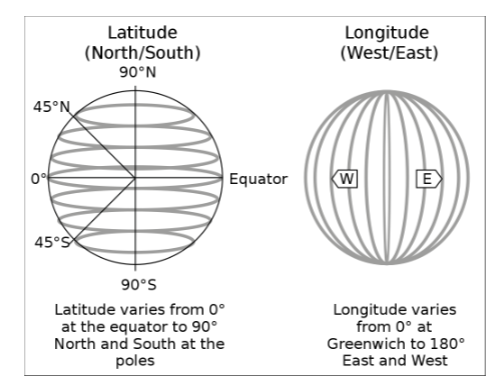
Day = storms.get("Date").apply(get_day))Latitude measures distance from the equator in the North or South direction. Longitude measures distance from the prime meridian in the East or West direction.
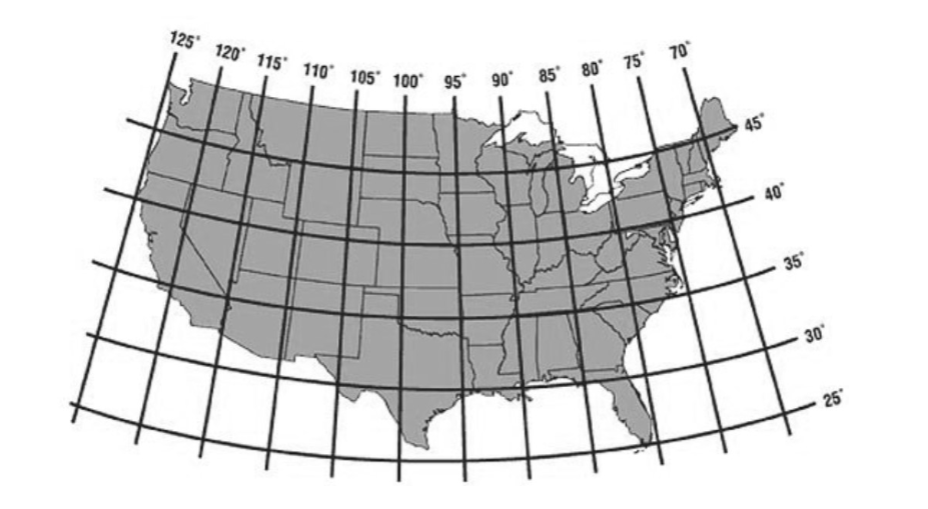
Since all of the United States lies north of the equator and west of
the prime meridian, the last character of each string in the
"Latitude" column of storms is
"N", and the last character of each string in the
"Longitude" column is "W". This means that we
can refer to the latitude and longitude of US locations by their
numerical values alone, without the directions "N" and
"W". The map below shows the latitude and longitude of the
continental United States in numerical values only.
lat_long_numerical that takes as
input a string representing a value from either the
"Latitude" or "Longitude" column of
storms, and returns that latitude or longitude as a
float. For example, lat_long_numerical(34.1N)
should return 34.1. def lat_long_numerical(lat_long):
return ________Hint: The string method .strip() takes as input
a string of characters and removes all instances of those characters at
the beginning and end of the string. For example,
"www.dsc10.com".strip("cmowz.") evaluates to
"dsc10".
What goes in the blank? To earn credit, your answer
must use the string method: .strip().
Answer: float(lat_long.strip("NW"))
According to the hint, .strip() takes as input of a
string of characters and removes all instances of those characters at
the beginning or the end of the string. The input we are given,
lat_long is the latitude and longitude, so we able to take
it and use .strip() to remove the "N" and
"W". However, it is important to mention the number we now
have is still a string, so we put float() around it to
convert the string to a float.
The average score on this problem was 70%.
Assume that lat_long_numerical has been correctly
implemented. Which of the following correctly replaces the strings in
the 'Latitude' and 'Longitude' columns of
storms with float values? Select all that
apply.
Option 1:
lat_num = storms.get('Latitude').apply(lat_long_numerical)
long_num = storms.get('Longitude').apply(lat_long_numerical)
storms = storms.drop(columns = ['Latitude', 'Longitude'])
storms = storms.assign(Latitude = lat_num, Longitude = long_num)Option 2:
lat_num = storms.get('Latitude').apply(lat_long_numerical)
long_num = storms.get('Longitude').apply(lat_long_numerical)
storms = storms.assign(Latitude = lat_num, Longitude = long_num)
storms = storms.drop(columns = ['Latitude', 'Longitude'])Option 3:
lat_num = storms.get('Latitude').apply(lat_long_numerical)
long_num = storms.get('Longitude').apply(lat_long_numerical)
storms = storms.assign(Latitude = lat_num, Longitude = long_num)Option 1
Option 2
Option 3
Answer: Option 1 and Option 3
Option 1 is correct because it applies the function
lat_long_numerical to the 'Latitude' and
'Longitude' columns. It then drops the old
'Latitude' and 'Longitude' columns. Then
creates new 'Latitude' and 'Longitude' columns
that contain the float versions.
Option 3 is correct because it applies the function
lat_long_numerical to the 'Latitude' and
'Longitude' columns. It then re-assigns the
'Latitude' and 'Longitude' columns to the
float versions.
Option 2 is incorrect because it re-assigns the
'Latitude' and 'Longitude' columns to the
float versions and then drops the 'Latitude' and
'Longitude' columns from the DataFrame.
The average score on this problem was 86%.
Important! For the rest of the exam, assume that the
'Latitude' and 'Longitude' columns of storms
now have numerical entries.
The Olympics are held every two years, in even-numbered years, alternating between the Summer Olympics and Winter Olympics. Summer Olympics are held in years that are a multiple of 4 (such as 2024), and Winter Olympics are held in years that are not a multiple of 4 (such as 2022 or 2026).
We want to add a column to olympics that contains either
"Winter" or "Summer" by applying a function
called season as follows:
olympians.assign(Season=olympians.get("Year").apply(season))Which of the following definitions of season is correct?
Select all that apply.
Notes:
We’ll ignore the fact that the 2020 Olympics were rescheduled to 2021 due to Covid.
Recall that the % operator in Python gives the
remainder upon division. For example, 8 % 3 evaluates to
2.
Way 1:
def season(year):
if year % 4 == 0:
return "Summer"
return "Winter"Way 2:
def season(year):
return "Winter"
if year % 4 == 0:
return "Summer"Way 3:
def season(year):
if year % 2 == 0:
return "Winter"
return "Summer"Way 4:
def season(year):
if int(year / 4) != year / 4:
return "Winter"
return "Summer"Way 1
Way 2
Way 3
Way 4
Answer: Way 1 and Way 4
return "Winter" line is before the if
statement. Since nothing after a return statement gets executed
(assuming that the return statement gets executed), no matter what the
year is this function will always return “Winter”. So, way 2 is
incorrect.2020 % 2 evaluates to 0. So, way 3 is
incorrect.year / 4 to an integer using int
changes its value. If the two aren’t equal, then we know that
year / 4 wasn’t an integer before casting, which means that
the year isn’t divisible by 4 and we should return
"Winter". If the code inside the if statement doesn’t
execute, then we know that the year is divisible by 4, so we return
“Summer”. So, way 4 is correct.
The average score on this problem was 89%.
Since Janine’s knowledge of who holds each card will change
throughout the game, the clue DataFrame needs to be updated
by setting particular entries.
Suppose more generally that we want to write a function that changes
the value of an entry in a DataFrame. The function should work for any
DataFrame, not just clue.
What parameters would such a function require? Say what each parameter represents.
Answer: We would need four parameters:
df, the DataFrame to change.
row, the row label or row number of the entry to
change.
col, the column label of the entry to
change.
val, the value that we want to store at that
location.
The average score on this problem was 43%.
Suppose the function first_two takes as input a string
and returns a string with the first two characters only. For example
first_two("panda") is "pa". Using this
function, write an expression that evaluates to a Series containing the
two-character airline designator for each flight in
flights.
Answer:
flights.get("flight_num").apply(first_two)
The average score on this problem was 78%.
While browsing the library, Hermione stumbles upon an old book containing game logs for all Quidditch matches played at Hogwarts in the 18th century. Quidditch is a sport played between two houses. It features three types of balls:
Quaffle: Worth 10 points when used to score a goal.
Bludger: Does not contribute points. Instead, used to distract the other team.
Snitch: Worth 150 points when caught. This immediately ends the game.
A game log is a list of actions that occurred during a Quidditch
match. Each element of a game log is a two-letter string where the first
letter represents the house that performed the action ("G"
for Gryffindor, , "H" for Hufflepuff, "R" for
Ravenclaw, "S" for Slytherin) and the second letter
indicates the type of Quidditch ball used in the action
("Q" for Quaffle, "B" for Bludger,
"S" for Snitch). For example, "RQ" in a game
log represents Ravenclaw scoring with the Quaffle to earn 10 points.
Hermione writes a function, logwarts, to calculate the
final score of a Quidditch match based on the actions in the game log.
The inputs are a game log (a list, as described above) and the full
names of the two houses competing. The output is a list of length 4
containing the names of the teams and their corresponding scores.
Example behavior is given below.
>>> logwarts(["RQ", "GQ", "RB", "GS"], "Gryffindor", "Ravenclaw")
["Gryffindor", 160, "Ravenclaw", 10]
>>> logwarts(["HB", "HQ", "HQ", "SS"], "Hufflepuff", "Slytherin")
["Hufflepuff", 20, "Slytherin", 150]Fill in the blanks in the logwarts function below. Note
that some of your answers are used in more than one
place in the code.
def logwarts(game_log, team1, team2):
score1 = __(a)__
score2 = __(a)__
for action in game_log:
house = __(b)__
ball = __(c)__
if __(d)__:
__(e)__:
score1 = score1 + 10
__(f)__:
score1 = score1 + 150
else:
__(e)__:
score2 = score2 + 10
__(f)__:
score2 = score2 + 150
return [team1, score1, team2, score2]What goes in blank (a)?
Answer: 0
First inspect the function parameters. With the example
logwarts(["RQ", "GQ", "RB", "GS"], "Gryffindor", "Ravenclaw"),
we observe game_log will be a list of strings, and
team1 and team2 will be the full name of the
respective competing houses. We can infer from the given structure that
our code will
Initialize two scores variables for the two houses,
Run a for loop through all the entries in the list, update score based on given conditions,
Return the scores calculated by the loop.
To set up score_1 and score_2 so we can
accumulate them in the for loop, we first set both equal to 0. So blank
(a) will be 0.
The average score on this problem was 89%.
What goes in blank (b)?
Answer: action[0]
We observe the for loop iterates over the list of actions, where each
action is a two letter string in the
game_log array. Recall question statement- “Each element of
a game log is a two-letter string where the first letter represents the
house that performed the action”. Therefore, to get the house, we will
want to get the first letter of each action string. This is accessed by
action[0].
Note: A common mistake here is using action.split()[0].
Recall
what split() does/) - it takes in a string, splits it
according to the delimiter given (if not given, it separates by blank
space), and returns a list of separated strings. This
means that action.split()[0] will actually return itself.
Example: if action is "RQ",
action.split() will split "RQ" by blank space,
in this case, there are none; so it will return the one-element list
["RQ"]. Accessing the zero-th index of this list by
action.split()[0] gives us "RQ" back, instead
of what we actually want ("R").
The average score on this problem was 61%.
What goes in blank (c)?
Answer: action[1]
Following the same logic as blank (b), we get the type of ball used
in the action by accessing the second character of the string, which is
action[1].
The average score on this problem was 62%.
What goes in blank (d)?
Answer: house == team1[0]
Now enter the fun part: to figure out the correct conditions of the if-statments, we must observe the code inside our conditional blocks carefully.
Recall question statement:
For each entry of the game log, the house is represented by the first letter. “G” for Griffindor, “H” for Hufflepuff, “R” for Ravenclaw, “S” for Slytherin.
Quaffle (“Q”) gets 10 points,
Snitch (“S”) gets 150 points,
Bludger (“B”) gets no point.
score1 is the score of the first team, and
score2 is the score of the second.
We have two conditions to take care of, the house and the type of
ball. How on earth do we know which one is nested and which one is on
the outside? Observe in the first big if statment, we are only updating
score1. This means this block takes care of the score of
the first house. Therefore, blank (d) should set the condition for the
first house.
Now careful! team1 and team2 are given as
full house names. We can match the house variable by
getting the first letter of the each team string (e.g. if
team1 is Griffindor, we will get “G” to match with “G”). We
want to match house with team1[0], so our
final answer is house == team1[0]. Since there are only two
houses here, the following else block will take care of
calculating score for the second house using the same scoring scheme as
we do for the first house.
The average score on this problem was 74%.
What goes in blank (e)?
Answer: if ball == "Q"
After gracefully handling the outer conditional statement, the rest
is simple. We now simply condition the scores. Here, we see score1
increments by 10, so we know this is accounting for a Quaffle. Recall
ball variable represents the type of ball we have. In this
case, we use if ball == "Q" to filter for Quaffles.
The average score on this problem was 69%.
What goes in blank (f)?
Answer: elif ball == "S" or
if ball == "S"
Using the same logic as blank (e), since the score is incremented by
150 here, we know this is a snitch. Using elif ball == "S"
or if ball == "S" will serve the purpose. We do not need to
worry about bludgers, since those do not add to the score.
The average score on this problem was 64%.
Suppose we have access to another DataFrame called
orders, containing all student dining hall orders from the
past three years. orders includes the following columns,
among others:
"Dining Hall" (str): The dining hall
where the order was placed.
"Start" (str): The time the order was
placed.
"End" (str): The time the order was
completed.
All times are expressed in 24-hour military time format (HH:MM). For
example, "13:15" indicates 1:15 PM. All orders were
completed on the same day as they were placed, and "End" is
always after "Start".
Fill in the blanks in the function to_minutes below. The
function takes in a string representing a time in 24-hour military time
format (HH:MM) and returns an int representing the number of minutes
that have elapsed since midnight. Example behavior is given below.
>>> to_minutes("02:35")
155
>>> to_minutes("13:15")
795
def to_minutes(time):
separate = time.__(a)__
hour = __(b)__
minute = __(c)__
return __(d)__Answer (a): split(":")
We first want to separate the time string into hours and minutes, so
we use split(":") to turn a string like
"HH:MM" into a list of the form
["HH", "MM"].
The average score on this problem was 84%.
Answer (b): separate[0] or
int(separate[0])
The hour will be the first element of the split list, so we can
access it using separate[0]. This is a string, which we can
convert to an int now, or later in blank (d).
The average score on this problem was 73%.
Answer (c): separate[1] or
int(separate[1])
The minute will be the second element of the split list, so we can
access it using separate[1] or separate[-1].
Likewise, this is also a string, which we can convert to an
int now, or later in blank (d).
The average score on this problem was 73%.
Answer (d):
int(hour) * 60 + int(minute) or
hour * 60 + minute (depending on the answers to (b) and
(c))
In order to convert hours and minutes into minutes since midnight, we
have to multiply the hours by 60 and add the number of minutes. These
operations must be done with ints, not strings.
The average score on this problem was 73%.
Fill in the blanks below to add a new column called
"Wait" to orders, which contains the number of
minutes elapsed between when an order is placed and when it is
completed. Note that the first two blanks both say (e)
because they should be filled in with the same value.
start_min = orders.get("Start").__(e)__
end_min = orders.get("End").__(e)__
orders = orders.assign(Wait = __(f)__)Answer (e): apply(to_minutes)
In order to find the time between when an order is placed and
completed, we first need to convert the "Start" and
"End" times to minutes since midnight, so that we can
subtract them. We apply the function we wrote in Problem 3.1 to get the
values of "Start" and "End" in minutes elapsed
since midnight.
The average score on this problem was 87%.
Answer (f): end_min - start_min
Now that we have the values of "Start" and
"End" columns in minutes, we simply need to subtract them
to find the wait time. Note that we are subtracting two Series here, so
the subtraction happens element-wise by matching up corresponding
elements.
The average score on this problem was 87%.
You were told that "End" is always after
"Start" in orders, but you want to verify if
this is correct. Fill the blank below so that the result is
True if "End" is indeed always after
"Start", and False otherwise.
(orders.get("Wait") > 0).sum() == __(g)__Answer (g): orders.shape[0]
Since "Wait" was already calculated in the previous
question by subtracting "End" minus "Start",
we know that positive values indicate where "End" is after
"Start". When we evaluate
orders.get("Wait") > 0, we get a Boolean Series where
True indicates rows where "End" is after
"Start". Taking the .sum() of this Boolean
Series counts how many rows satisfy this condition, using the fact that
True is 1 and False is
0 in Python. If "End" is always after
"Start", this sum should equal the total number of rows in
the DataFrame, which is orders.shape[0]. Therefore,
comparing the sum to orders.shape[0] will return
True exactly when "End" is after
"Start" for all rows.
The average score on this problem was 36%.
Fill in the blanks below so that ranked evaluates to an
array containing the names of the dining halls in orders,
sorted in descending order by average wait time.
ranked = np.array(orders.__(h)__
.sort_values(by="Wait", ascending=False)
.__(i)__)Answer (h):
groupby('Dining Hall').mean()
Since we want to compare the average wait time for each Dining Hall
we know we need to aggregate each Dining Hall and find the mean of the
"Wait" column. This can be done using
groupby('Dining Hall').mean().
The average score on this problem was 62%.
Answer (i): index or
reset_index().get('Dining Hall')
The desired output is an array with the names of
each dining hall. After grouping and sorting, the dining hall names
become the index of our DataFrame. Since we want an array of these names
in descending order of wait times, we can either use .index
to get them directly, or reset_index().get("Dining Hall")
to convert the index back to a column and select it.
The average score on this problem was 43%.
What would be the most appropriate type of data visualization to compare dining halls by average wait time?
scatter plot
line plot
bar chart
histogram
overlaid plot
Answer: bar chart
"Dining Hall" is a categorical variable and the average
wait time is a numerical variable, so a bar chart should be used. Our
visualization would have a bar for each dining hall, and the length of
that bar would be proportional to the average wait time.
The average score on this problem was 89%.
Fill in the body of the function prep_time such that
both expressions below evaluate to the same Series.
blue_bowl.get("num_toppings").apply(prep_time)
1.2 + 0.2 * blue_bowl.get("num_toppings")
def prep_time(x):
return Answer: 1.2 + .2 * x
The average score on this problem was 80%.
If there are zero modifications made to a drink, the entry in the
modifications column will be 'none'.
Otherwise, all modifications will be distinct and separated by a
'+' without any spaces. Complete the function
count_mods, whose input is a single string formatted like
the entries in the modifications column of
orders. The function should return the number of
modifications in the drink order. Then, use the count_mods
function to assign a new column to orders called
num_mods, which describes the number of modifications made
to each drink in orders. For example, the entries of the
num_mods column for rows 0, 1, 2 should be 2, 1, 0,
respectively.
def count_mods(mod):
if ___(a)___:
return 0
else:
return len(___(b)___)
orders = orders.assign(num_mods=___(c)___)(a):
Answer: mod == 'none'
If there are no modifications, the string stored in
modifications is exactly 'none', so we return
0 in that case.
The average score on this problem was 77%.
(b):
Answer: mod.split('+')
When there are modifications, they are distinct pieces separated by
'+' with no spaces. Splitting on '+' gives one
string per modification, so len(...) is the number of
modifications (e.g. "vanilla+lavender" → 2,
"caramel" → 1).
The average score on this problem was 76%.
(c):
Answer:
orders.get('modifications').apply(count_mods)
Apply count_mods to each value in the
modifications column to compute the new column
num_mods for every row.
The average score on this problem was 80%.